Kapitel 4 Fragebogen
Im Gegensatz zu qualitativen Interviews weisen quantitative Befragungen mit einem standardisierten Fragebogen einen höheren Grad an Struktur auf. Hier werden nicht nur die angesprochenen Themen und Fragen bezüglich ihrer Anzahl, Reihenfolge und Formulierung festgelegt, sondern auch die Art und Weise der Antwort.
Der Aufbau eines strukturierten Fragebogens umfasst verschiedene Komponenten. Zunächst gibt es ein allgemein formuliertes Thema der Befragung und eine Ansprache an die Zielgruppe. Bereits hier entscheidet der Angesprochene oft mehr oder weniger bewusst, ob und wie er sich zu dem Thema äußern wird.

Darüber hinaus werden dem Befragten in der Anleitung Vorgaben gemacht, wie die Befragung ablaufen wird und nach welchem Schema die Antworten erwartet werden. Dies kann dazu führen, dass der Befragte sich der Befragung entzieht, insbesondere wenn spezifische Themen angesprochen werden, die der Befragte nicht einschätzen oder behandeln möchte.
Zusätzliche Angaben, die eigentlich dazu dienen sollen, die Stichprobe zu beschreiben und greifbarer zu machen, können ebenfalls dazu führen, dass der Befragte sich gegenüber der Befragung verschließt. Selbst eine explizite Zusicherung von Anonymität kann nicht überzeugend sein, wenn andererseits nach objektiven Unternehmensdaten und namentlich nach Kooperationspartnern gefragt wird.
Die Antworten resultieren aus kognitiven Entscheidungsprozessen und die Bewertungen in Form von Zustimmung oder Ablehnung unterliegen der Subjektivität individueller Ziele, persönlicher Annahmen und Erwartungen. Das Modell der Antwortgenese Tränkle (1983, S. 232) bietet einen theoretischen Rahmen und legt nahe, dass Antworten auf Fragen nicht nur durch die Persönlichkeitseigenschaften der Person beeinflusst werden, sondern auch durch kognitive Prozesse wie das Verstehen der Frage, die Suche nach relevanten Informationen im Gedächtnis und die Formulierung einer Antwort.
Neben der Antwortbereitschaft sind Frage- und Antwortverständnis wichtig, um wahre Aussagen in Befragungen zu erhalten. Anderenfalls resultieren bedeutungslose Antworten oder falls eine Antworttendenz vorherrscht (z.B. “ich kreuze immer rechts an”), dann resultieren systematische Antworten ohne einen inhaltlichen Bezug zur Frage. Ähnlich ist es, wenn die wahre Antwort dem Befragten gar nicht bekannt ist.
Falls der Befragte zumindest eine sozial erwünschte Antwort kennt, hat der Befragte die Wahl zwischen einer zweckmäßigen Antwort und der inhaltslosen.
Aber auch wenn dem Befragten die subjektiv wahre Antwort bekannt ist, kann die Antwort als Ergebnis des individuellen Abwägens von subjektivem Nutzen angesehen werden, dass gegebenenfalls in einer zweckmäßig verfälschten Antwort resultiert.
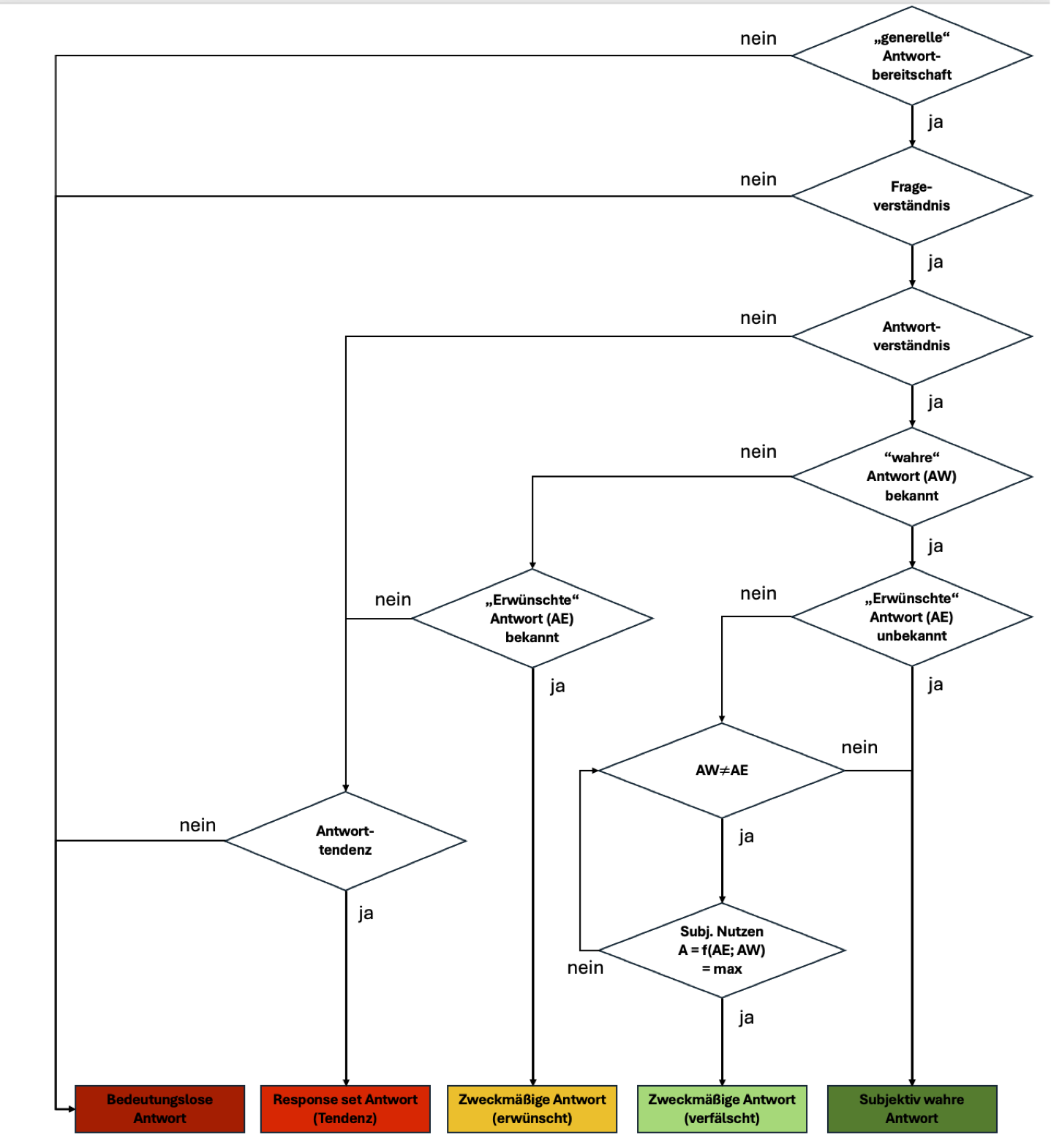
Auch solche Überlegungen können dazu beitragen, die Gültigkeit und Reliabilität von Fragebögen zu beurteilen und zu verbessern, indem es Einblicke in die kognitiven Prozesse liefert, die bei der Beantwortung von Fragen auftreten.
Es wird davon ausgegangen, dass auch das Ausbleiben einer inhaltlichen Antwort (Nichtbeantwortung oder Neutrale Enthaltung) an sich einen Antwortgehalt aufweisen und Verfälschungstendenzen (z.B. sozial erwünscht zu antworten) oder “responsesets” (z.B. Zustimmungstendenz) die Verwertbarkeit der Daten nicht per se herabstufen. Stattdessen ist die Betrachtung von “response styles” ein eigenes Forschungsgebiet. Dennoch sind eine grundlegende Bereitschaft zur Befragung, die Befähigung zum Verständnis der Frage sowie die Möglichkeit und Relevanz der Antwort entscheidende Aspekte der Gestaltung von Fragebogen und Erhebung.
4.1 Rechtliche Rahmenbedingungen
Die Auswahl und die Selektion der Untersuchungsteilnehmer bedingen erhebliche Einschränkung die Ergebnisse einer Stichprobe auf die Grundgesamtheit zu übertragen. Den Verzerrungen durch Unwissenheit und Unverständnis kann durch eine angemessene Auswahl der Informanten sowie klaren, unmissverständlichen Fragen begegnet werden.
Der Umgang mit der fehlenden Bereitschaft für Befragungen sowie Verzerrungen durch zweckmäßige Antworten, betrifft darüber hinaus auch den Umgang mit personenbezogenen oder personenbeziehbaren Daten. In allen Datenerhebungen (wie z.B. Umfragen) sind die Teilnehmer durch eine Datenschutzerklärung über den Zweck, die Form und den Umfang der Erhebung und Verarbeitung zu informieren und müssen dieser auch in Form einer Einwilligungserklärung zustimmen.
Beispiel für eine Einwilligungserklärung:
Auf den folgenden Seiten wollen wir Ihnen ein paar Fragen zu dem Thema ‘Digitalisierung’ stellen. Ziel unserer Befragung ist es, den Einsatz von Digitalisierung in Unternehmen besser bewerten zu können. Vor der Befragung werden wir nähere Informationen zu Ihrer Person (Firma, Alter, Geschlecht, Position im Unternehmen etc.) abfragen.
Die Befragungsdaten werden ausschließlich zu wissenschaftlichen Zwecken genutzt und es wird sichergestellt, dass ihre personenbezogenen und personenbeziehbaren Daten nicht mit Ihren Angaben in Verbindung gebracht werden können.
Die Teilnahme an dieser Umfrage ist ohne Nennung Ihres Namens und ohne Registrierung möglich. Vor Abschluss der Befragung erhalten Sie die Möglichkeit, Ihre Angaben in einer Gesamtansicht zu prüfen oder zu ändern. Gemäß den datenschutzrechtlichen Bestimmungen haben Sie gegenüber dem Informationsträger das Recht auf Auskunft sowie Löschung Ihrer personenbezogenen Daten. Sie können die Einwilligungserklärung jederzeit widerrufen.
4.2 Entwicklungen
All diese Betrachtungen zeigen auf, dass Fragebogenerhebungen und -entwicklungen keine einmaligen Ereignisse, sondern einen iterativen Prozess darstellen. Die fortlaufenden Anpassungen und Verfeinerungen von Fragen und Antworten basierend auf Testläufen, dem Feedback der Teilnehmer, der statistischer Analyse und dem Ziel der Befragung. Die iterative Natur ermöglicht die kontinuierliche Verbesserung der Erhebungsinstrumente, um genauere und relevantere Daten zu erhalten.
In den Datenerhebungen des Lehrstuhls wurden in den letzten 10 Jahren verschiedene Themenbereiche wie Zusammenarbeit in Wertschöpfungsketten, Innovationskooperationen, Digitalisierung und die Bedingungen in Coworking Spaces behandelt, in denen unter anderem die strategische Ausrichtung von Unternehmen, wie die Ausprägung einer Innovationsstrategie, der Pionier- und Folgerstrategie sowie der Kooperationsstrategie, befragt wurden.
Solche Begriffe, die im eigentlichen Sinne theoretische Konstrukte sind, lassen sich tatsächlich nicht wirklich objektiv messen (Ratzmann, 2016). Das liegt darin begründet, dass die Verwendung solcher Konstrukte nicht die Realität an sich widerspiegelt, sondern Vorstellungen von Wirklichkeit (Modelle) sind. Einige dieser Begriffe haben sich jedoch als nützlich für das Verständnis der Realität erwiesen und spielen “sowohl im gesellschaftlichen als auch im betriebswirtschaftlichen Kontext eine zentrale Rolle” (Ratzmann, 2016 V).
So wurde der Begriff der Innovation in seinem “traditionellen Verständnis als soziologisches oder ökonomisches Phänomen aufgefasst” (Ratzmann, 2016, S. 7), der zwischenzeitlich selbst einem Wandel unterliegt, und “in unterschiedlichsten Gesellschaftsbereichen gleichsam als Leitgedanke und Deutungsmuster auftritt” (ebenda).
Innovationen sind “auf zukünftiges ausgerichtet - dessen Verwirklichung kann empirisch gesichert jedoch erst ex-post beobachtet und bewertet werden” (Bormann, 2012, S. 40). Aus diesem Verständnis heraus sind Innovationen strategische Ausrichtungen auf eine zukünftige Gegenwart, während die Forschung die Indikatoren für Innovation retrospektiv aus dem Rückblick auf vergangene Ereignisse bezieht (ebenda).
Dies führt zwangsläufig zu der Herausforderung, wie ein solcher theoretischer Begriff in der Forschung messbar gemacht werden kann. Einerseits wurde durch die Veröffentlichung des Oslo-Manuals ein Konsens erreicht, wonach “Aktivitäten und Investitionen, die auf Forschung und Entwicklung ausgerichtet sind, als Indikatoren für Innovation angesehen werden” (Ratzmann, 2016, S. 1).
Andererseits wurden verschiedene Kategorisierungen für Innovationen vorgenommen. Eine weit verbreitete Konzeption in der Forschung unterscheidet Innovationen in der inhaltlichen, Intensitäts-, Subjekt-, Prozess- und normativen Dimension (Hausschild, 2005, S. 23).
Dadurch können beispielsweise Produktinnovationen von Prozessinnovationen auf der inhaltlichen Dimension abgegrenzt werden, und Neuprodukte als radikale Innovationen in der Intensitätsdimension von Weiterentwicklungen (sogenannten inkrementellen Innovationen). Darüber hinaus kann auf der Subjektdimension der Innovation unterschieden werden, für wen die Innovation neu ist. Die prozessuale Dimension beschreibt, wo die Neuerung beginnt und endet, und die normative Dimension umfasst die Frage, ob ‘neu’ auch mit ‘erfolgreich’ (bzw. mit Verbesserung) gleichzusetzen ist.
In der Entwicklung des Fragebogens wurden drei Items identifiziert, die Auskunft über den Innovationserfolg von Unternehmen geben:
Unsere neuen Produkte und Services … 1) sind innovative Durchbrüche. 2) enthalten technologische Fortschritte, die alte Technologien obsolet machen. 3) bedienen vollständig neuen Nutzen für die Kunden.
Auf der inhaltlichen Dimension ist die Innovationserfolgsmessung hier auf Produkte und Dienstleistungen ausgerichtet. Die Messung eignet sich also nicht, um Prozessinnovationen zu beurteilen. Die Intensitätsdimension ist auf radikale Innovationen ausgerichtet.
Die Innovationen eines Unternehmens, dass auf die Verbesserung bestehender Technologien (inkrementelle Innovation) ausgerichtet ist, würde mit dieser Messung grundsätzlich schlechter bewertet werden. Die Subjektdimension der Messung ist auf den Kunden ausgerichtet. Die prozessuale Dimension von Innovation wird durch die Obsoleszenz bestimmt, also durch die Tatsache, dass die Erneuerung die bestehende Technologie verdrängt. Die normative Dimension von Innovation wird tendenziell indirekt durch die Dominanz gegenüber dem Bestehenden bestimmt.
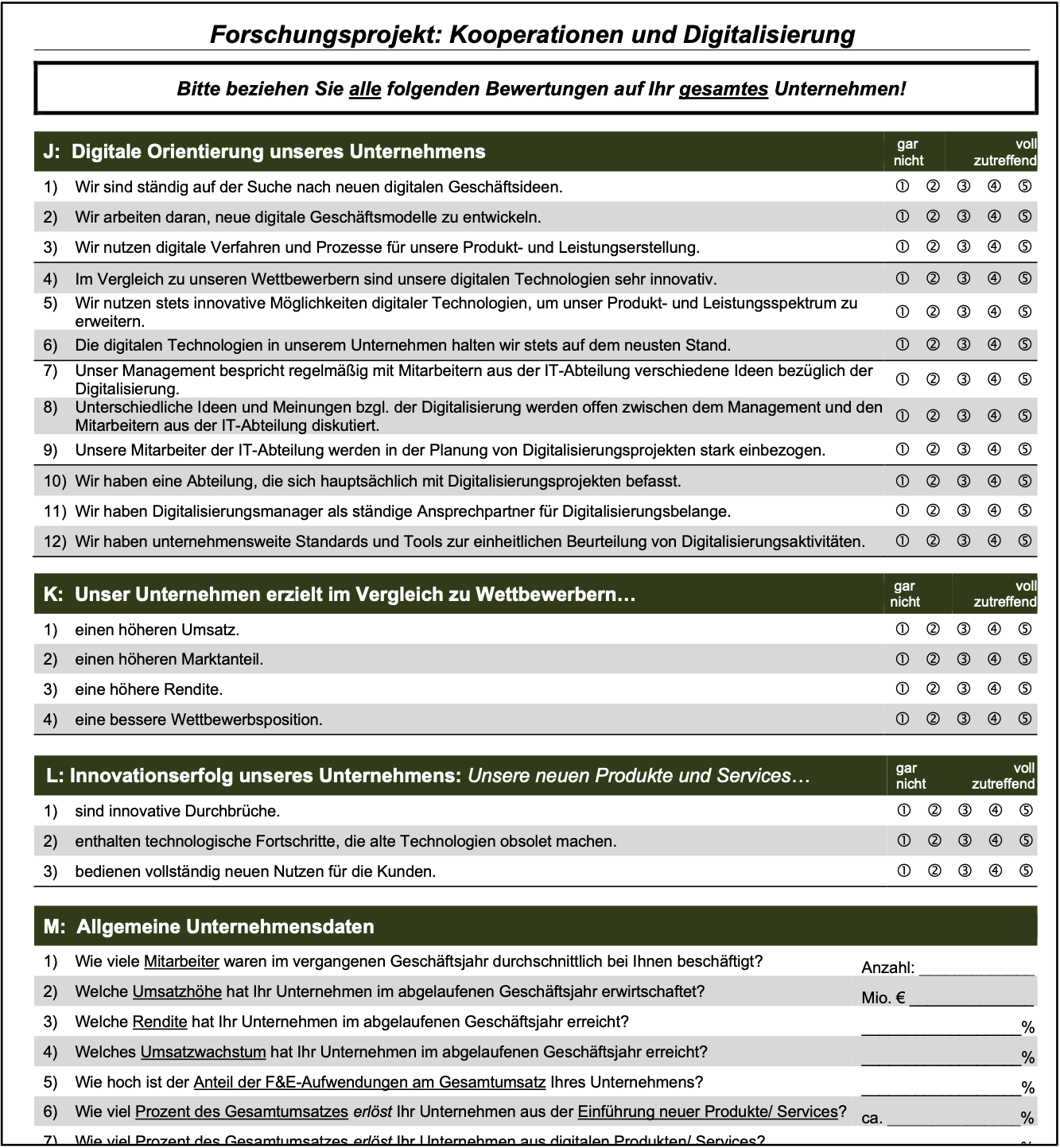
In der Regel sind für die Fragen und Aussagen in einem Fragebogen Antwortmöglichkeiten vorgegeben. Der Befragte kann dann zwischen Antwortalternativen entscheiden oder er kann eine oder mehrere Antworten aus einem Set vorgegebener Alternativen auswählen.
Die eigentliche Messung besteht also in der Skalierung, der Zuordnung eines numerischen Wertes, der über Ablehung oder Zustimmung informiert (Bortz, 1993, S. 19; Schnell, Hill & Esser, 2008, S. 138). Messungen sind also Skalierungen und bedürfen einer Skala, hier einer metrischen Skala mit den Antwortmöglichkeiten von ‘1’ bis ‘5’, wobei die ‘1’ für vollständige Ablehnung und die ‘5’ für vollständige Zustimmung steht.
4.3 Skalen
Eine Skala bezieht sich auf die Reihe von Werten oder Kategorien, die zur Messung eines bestimmten Merkmals verwendet werden. Sie kann nominal (benannt), ordinal (geordnet), intervall (mit gleichem Abstand zwischen den Werten) oder metrisch (mit einem absoluten Nullpunkt) sein. Eine Skala definiert also die Bandbreite und den Umfang der Messung.
Mit der Auswahl einer Antwortskala (Carifio & Perla, 2007; Likert, 1932) wird zum großen Teil darüber entschieden, wie die Daten später ausgewertet und ob bestimmte Testverfahren eingesetzt werden können.
Nominalskalen werden eingesetzt, um qualitative oder kategoriale Daten zu erfassen, bei denen keine Reihenfolge oder Rangfolge zwischen den Kategorien besteht. Die Zuordnung der Zahlen stellt hier lediglich eine Bennennung dar. Ein Merkmal ist vorhanden oder nicht vorhanden.
In unserem Fragebogen verwenden wir Nominalskalen zum Beispiel um den Einsatz von digitalen Technologien in Unternehmen zu befragen. Der Befragte bekommt die Möglichkeit, mit einem Kreuz zu markieren, welche Technologien verwendet werden. Für jede “Kategorie” von Technologie wird einzeln entschieden, ob sie eingesetzt wird oder nicht. In der späteren Datenanalyse, wird jedes Kreuz mit “1” kodiert und Antwortfelder, in denen kein Kreuz vorhanden ist, wird mit “0”kodiert.

Solche Skalen eignen sich, um die Häufigkeit der einzelnen Technologien zu bestimmen. In einer Befragung von n=174 Unternehmen im Jahr 2017 gaben 47% der befragten Unternehmen an, dass sie Social Media zu nutzen und 22% gaben an, dass sie Big Data einsetzen. In einer weiteren Befragung im Jahr 2020 wurden in n=287 Unternehmen nahezu identische Häufigkeiten (Einsatz von Social Media: 39% und Big Data: 21%) bestimmt. Falls Mittelwerte aus den Nominalskalen berechnet werden, spiegelt der Mittelwertdann einfach die durchschnittliche relative Häufigkeit der Kategorie wider, welche in den Daten mit “1” kodiert wurde.
Die letze Kategorie der Frage nach eingesetzten Technologien beinhaltet zudem eine Besonderheit. Die Kategorie “Andere” ist um ein “offenes” Feld erweitert, in dem die Befragten nach eigenem Ermessen Eintragungen vornehmen können, soweit sie es für notwendig halten.
Die meisten unserer Messungen beziehen sich jedoch auf Ordinalskalen. Dabei handelt es sich um Skalen, durch die eine Ordnung oder Rangfolge vorgegeben wird, ohne jedoch die Abstände zwischen den Werten zu quantifizieren.
Dabei geht es häufig um die Häufigkeit, Intensität, Wahrscheinlichkeit, Qualität oder Zustimmung zu Aussagen oder Zuständen, um Einstellungen und Zustände zu bewerten. Wenn bspw. ein Rating, also eine Bewertung darüber erfragt wird, wie groß der Einfluss des Befragten auf Digitalisierungsprojekte ist, können wir ableiten, dass Befragte die hier mit „gar nicht“ antworten weniger Einfluss aufweisen, als diejenigen Befragten, die hier mit „voll zutreffend“ antworten.

Die entsprechend zugewiesenen Werte von 1 und 5 lassen diese direkte Vergleichbarkeit zu. Wie bei Schulnoten lässt sich jedoch nicht behaupten, das die Note 2 eine doppelt so gute Leistung darstellt, wie die Note 4. Dies ist der entscheidende Unterschied zu Intervallskalen. Die Bezeichnung der Skalenkategorien (verbale Marken) haben eine entscheidende Bedeutung für die inhaltliche Interpretation und die zu erwartende Verteilung der Antworthäufigkeiten.
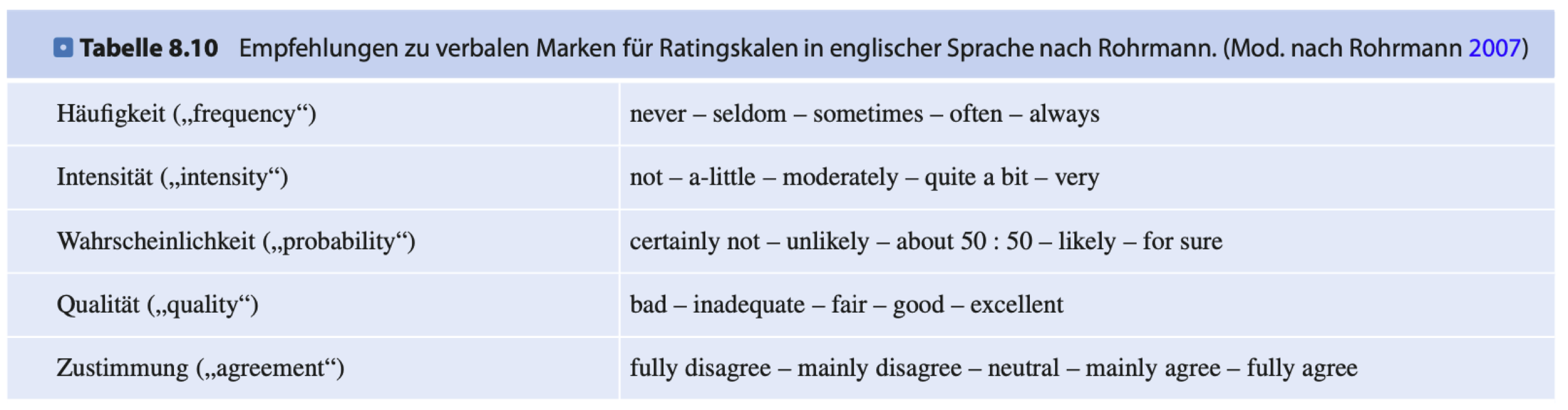
Bei der Intervallskala werden gleiche Abstände zwischen den Maßen vorausgesetzt.
Wenn der Befragte z. B. mit Item A2 angibt, seit 12 Monaten in aktuellen Position arbeitet, dann kann dargestellt werden, dass er dort doppelt so lange wie sein Kollege, der seine Position seit 6 Monaten einnimmt, beschäftigt ist. Dies ist jedoch keine Intervallskala, sondern eine metrische Skala.

4.4 Klassische Testtheorie
Die Klassische Testtheorie (KKT) basiert auf dem Grundsatz (Axiom), dass jede Messung auch einen Messfehler einschließt. Dieses Wissen aus dem Forschungsgebiet der Testtheorie gibt dem Forscher also zu bedenken, dass er gar nichts fehlerfrei messen kann. Diese Tatsache kann auf den ersten Blick frustrierend wirken, bietet aber auch eine Chance. Wenn es nämlich möglich wäre, diesen Fehler zu bestimmen, könnte der wahre Wert des zu messenden Objekts als Differenz von Messwert und Messfehler bestimmt werden.
Ein zweiter Grundsatz der KTT besagt, dass es keinen systematischen Zusammenhang zwischen dem wahren Wert einer Messung und ihrem Messfehler gibt.
Daraus kann ableitet werden, dass sich bei der wiederholten Messung eines Objektes zwar immer unterschiedliche Messwerte ergeben, wenn sich jedoch der wahre Wert des zu messenden Objekts nicht verändert, dann werden die Unterschiede ausschließlich durch die Messfehler bestimmt sein.
Wenn zudem angenommen werden kann, dass der Messfehler eine Normalverteilung aufweist, dann werden sich Über- und Unterschätzungen des wahren Wertes (also die Messfehler) bei wiederholten Messungen gegenseitig aufheben. Dabei ist es unerheblich, ob es sich um eine Wiederholungsmessung desselben Items oder um eine parallele Messung (mit einem ähnlichen Item) handelt.
Diese Idee ist bereits im Zusammenhang mit der Reliabilität angesprochen worden. Die mögliche Austauschbarkeit von Items zur Messung eines Merkmales oder einer Eigenschaft sind demnach eine Bedingung für einen hohen Wert von Cronbachs \(\alpha\), dem Koeffizenten der Äquivalenz.
Systematische Messfehler, dass sind Fehler, die aufgrund von konsistenten, wiederholbaren Ursachen auftreten und zu einer systematischen Verzerrung der Messergebnisse führen, können fälschlicherweise zu hoher Äquivalenz führen. Dies bedeutet, dass Messungen oder Daten, die auf unterschiedliche Weise erhoben werden, zu ähnlichen Ergebnissen führen, obwohl diese tatsächlich auf Fehlern beruhen. Diese Situation führt zu falschen Schlussfolgerungen, da die Daten konsistent sind, obwohl sie die Realität nicht korrekt abbilden.
Um die Genauigkeit von Messungen sicherzustellen, ist es daher wichtig, systematische Fehler zu identifizieren und zu minimieren. Dies kann durch sorgfältige Auswahl und Kalibrierung von Messinstrumenten, standardisierte Messverfahren, Kontrolle von Störfaktoren und regelmäßige Überprüfung der Messergebnisse erfolgen. So kann die Zuverlässigkeit und Validität der erhobenen Daten verbessert werden, um fundierte Entscheidungen und Schlussfolgerungen zu ermöglichen.
Vor diesem Hintergrund ist es ratsam, mehrere Items als Indikatoren für die interessierenden theoretischen Konstrukte zu finden und einzusetzen. Bereits mit der Verwendung von zwei Items “können zufällige Messfehler kontrolliert werden … [und durch den Einsatz von drei Items (Indikatoren) kann] … auch systematischen Messfehlern Rechnung getragen werden” (Brown, 2006; Latcheva & Davidov, 2014, S. 749).
4.5 Index und Messmodell
Ein Index ist eine Größe aus aggregierten Messwerten, die dazu dient, komplexe Konstrukte oder Phänomene zu operationalisieren und zu messen, indem mehrere Indikatoren oder Variablen zu einer einzigen Kennzahl oder einem einzigen Wert kombiniert werden.
Der Human Development Index (HDI) ist ein Beispiel für einen Index, der von den Vereinten Nationen entwickelt wurde um den Entwicklungsstand eines Landes zu messen. Er umfasst die drei Dimensionen Lebenserwartung, Bildungsstand und Lebensstandard.
Jede dieser Dimensionen wird durch spezifische Indikatoren gemessen: Lebenserwartung durch die durchschnittliche Lebenserwartung bei der Geburt, Bildungsstand durch die erwartete Schulzeit und die durchschnittliche Schulbesuchsdauer und Lebensstandard durch das Bruttonationaleinkommen (BNE) pro Kopf.
Der HDI wird verwendet, um Länder in Bezug auf ihren Entwicklungsstand zu vergleichen und Entwicklungsindikatoren im Laufe der Zeit zu verfolgen. Er ermöglicht es, Entwicklungsunterschiede zwischen Ländern aufzuzeigen und politische Maßnahmen zur Verbesserung des Lebensstandards und der Lebensqualität zu identifizieren.
Während ein Index eine praktische Methode ist, um Indikatoren zu kombinieren und ein bestimmtes Konstrukt zu messen oder darzustellen, bildet ein Messmodell die theoretische Grundlage, um die Beziehung zwischen Indikatoren und einem zugrunde liegenden Konstrukt zu beschreiben. Ein Messmodell kann auch verwendet werden, um die Gültigkeit und Zuverlässigkeit eines Index zu überprüfen, indem es die Beziehung zwischen den Indikatoren und dem Konstrukt erklärt.
“A measurement model specifies a structural model connecting latent variables to one or more measures or observed variables” (Bollen, 1989, S. 182).
4.6 Reflexives und formatives Messmodell
Wenn soziale oder strukturelle Eigenschaften oder Einstellungen gemessen werden sollen, müssen wir uns darüber Gedanken machen, anhand welcher messbaren Größen das Konstrukt operationalisiert werden soll. Das resultierende Messmodell dient dazu, das theoretische Konzept anhand beobachtbarer Variablen darzustellen
Eine essenzielle Unterscheidung betrifft, sowohl theoretisch als auch praktisch, wie das Konstrukt mit messbaren Indikatoren verbunden ist. Additive Verfahren wie Skalensumme, Skalenmittelwert oder Skalenprodukt sind Möglichkeiten, komplexe Konstrukte zu messen und zu operationalisieren, indem sie die gesamte Varianz aus mehreren Indikatoren in einer einzige aggregierte Größe zusammenfassen. Das zugrundliegende formative Messmodell verfolgt die theoretische Annahme, dass die Ausprägungen der messbaren Variablen, in der Testtheorie als manifeste Indikatoren bezeichnet, als Ursache für die Ausprägung des Konstruktes, in der Testtheorie als latente Variable bezeichnet, darstellt. Die Indikatoren in formativen Messmodellen können demnach unterschiedliche Dimensionen erfassen und müssen nicht miteinander korrelieren.
Dem gegenüber verweist die Bezeichnung reflexives Messmodell auf die Annahme, dass die Ausprägung einer latenten Variable als Ursache für die Ausprägung der manifesten Variablen verantwortlich ist. Die Indikatoren in einem reflektiven Messmodell spiegeln die Ausprägung dahinter liegende latente Variable wider (Bollen, 1989, S. 65). In diesem Messmodell eignen sich Indikatoren, wenn sie das zu erfassende Konstrukt möglichst präzise erfassen und möglichst keine Korrelation mit anderen Konstrukten aufweisen (Eindimensionalität). Das durch die Indikatoren repräsentierte reflektive Messmodell der latenten Variable ist nicht frei von Messfehlern. Diese streuen aber in der Regel unsystematisch um einen wahren Wert (vgl. Nitzl 2010; S.5).
Vor diesem Hintergrund verwenden wir sogenannte Multi-Item-Skalen und verbinden die Antworten auf die unterschiedlichen Items in einem sogenannten reflexiven Messmodell.
Ein reflektives Messmodell basiert auf der Annahme, dass unterschiedliche Ausprägungen der latenten Variable für die Variationen in den messbaren (manifesten) Variablen (Indikatoren) verantwortlich sind (Vinzi, 2010, S.50).
Jeder Indikator kann somit als (fehlerbehaftete) Messung des zugehörigen Konstruktes angesehen werden. Die messfehlerbedingten Verzerrungen werden durch die Zuordnung mehrerer Indikatoren zu einer latenten Variable verringert (Nitzl, 2010, S.8).