Kapitel 3 Datenerhebung
Ein essenzieller Bestandteil in jeder empirischen Untersuchung ist die Erhebung von Daten. Einige Sozialwissenschaftler unterscheiden bei der Erhebung nach qualitativen und quantitativen Methoden und nicht immer ist eine solche Klassifikation eindeutig oder sinnvoll. Der Einsatz der beiden Methoden weist auf die verschiedenen Fachrichtungen und Schulen innerhalb der Sozialforschung hin und im europäischen Raum nimmt Großbritannien bspw. einen Spitzenplatz bei den qualitativen Methoden ein, während die Niederlande stärker die quantitativen Methoden lehren. Idealerweise werden qualitative und quantitative Methoden nicht als Gegensätze, sondern als ergänzend angesehen (Baur & Blasius, 2022).
3.1 Qualitatives
Die Forschungslogik qualitativer Verfahren ist zirkulär und rekonstruktiv. Zirkulär meint, dass qualitative Verfahren vor allem einen explorativen und interpretativen Prozess der Formulierung und Re-Formulierung, Erhebung und Auswertung umfasst, der einem weniger standardisierten Ablauf folgt und in der Regel viele Phasen einschließt.
Auslöser für einen qualitativen Forschungsansatz kann ein konkretes Phänomen oder der Bezug auf eine Beobachtung sein. Die Beobachtung als Datenerhebung stellt jedoch - in Abgrenzung zu Alltagsbeobachtung - einen aktiven Prozess dar, bei dem Forschungsfragen zielgerichtet und systematisch geplant, dokumentiert aufbereitet und ausgewertet wird. Aus der anfänglichen Frage “Was ist hier los?” oder “Worum geht es hier?”, muss eine Fokussierung folgen, die in einer präzisen Frage mündet (Przyborski & Wohlrab-Sahr, 2014; Thierbach & Petschick, 2014).
Ein Thema wie z.B. “Wissen und Interaktion in Unternehmenskooperationen” bezeichnet einen Bereich, aber lässt die eigentlichen Forschungsfragen offen: “Welches Wissen ist für Unternehmen relevant?;”In welcher Weise interagieren Unternehmen?“;”Warum kooperieren Unternehmen obwohl sie Konkurrenten sind?” usw.
Die intensive Auseinandersetzung mit den verschiedenen Aspekten des Themas geht mit der Differenzierung der Fragestellung einher, ob qualitative Forschung notwendig ist, ob das Ergebnis bereits beforscht wurde oder ob sich das Ergebnis besser mit quantitativen Verfahren (z.B. einem standardisierten Fragebogen) erzielen lässt. Qualitative Forschung zielt darauf ab, ein tiefergehendes Verständnis für Phänomene, Erfahrungen und Prozesse zu gewinnen und Meinungen, Motivationen, Einstellungen und sozialen Interaktionen zu erkunden. Dabei werden zum Beispiel Beobachtungen, Interviews oder Inhaltsanalysen eingesetzt. Als Ergebnis können Daten in Form von Texten, Transkripten, Bildern oder anderen nicht-numerischen Formaten vorliegen.
3.2 Textanalyse
3.2.1 Inhaltsanalyse
Die Anwendung von Inhaltsanalysen stellt eine grundlegende Methode dar, um das Vorhandensein, die Bedeutung und den Kontext spezifischer Worte, Themen oder Konzepte in qualitativen Daten zu erfassen. Diese Daten können aus verschiedenen Quellen stammen, darunter Transkripte von Interviews mit offenen Fragen, Notizen, Nachrichten sowie Unternehmensberichten oder -präsentationen. Die fortschreitende Integration von Computern und ihre gestiegene Leistungsfähigkeit haben dazu geführt, dass computergestützte Textanalysen, bekannt als Computer-Aided-Text-Analysis (CATA), zunehmend an Bedeutung gewinnen. Diese Methodik bietet die Möglichkeit, qualitative und quantitative Forschungsansätze zu verbinden und eröffnet neue Perspektiven für die Analyse von Textdaten.
Innerhalb der Computer-Aided Text Analysis (CATA) lassen sich grundlegend zwei Ansätze unterscheiden:
Der erste Ansatz ist die induktive Inhaltsanalyse, bei der Worte oder Themen in Texten identifiziert werden, ohne dass vorherige Annahmen oder Hypothesen über den Inhalt bestehen. Dieser explorative Ansatz zielt darauf ab, die inhärenten Muster und Strukturen in den Daten zu erkunden. Die Ergebnisse können in Form von induktiven Wordlisten oder -wolken dargestellt werden, um beispielsweise die Häufigkeit bestimmter Begriffe zu visualisieren.
Ein konkretes Beispiel für eine induktive Wortanalyse ist die Untersuchung von Texten aus 34 Homepages von Coworking-Spaces, um zu klären, mit welchen Inhalten sich diese Räume und Unternehmen öffentlich darstellen. Für die Durchführung dieser Textanalyse wird die Softwareumgebung des R-Pakets “quanteda” genutzt, das eine effiziente und umfassende Unterstützung für Textanalysen bietet.
if(!require("readtext")) install.packages("readtext")
if(!require("quanteda")) install.packages("quanteda")
if(!require("quanteda.textplots")) install.packages("quanteda.textplots")
if(!require("quanteda.textstats")) install.packages("quanteda.textstats")
library (readtext)
library (quanteda)
library(quanteda.textplots)
library(quanteda.textstats)Zunächst wird der Text eingelesen und alle vorhandenen Worte (tokens) gesucht. Es sind weit mehr als 100.000 unterschiedliche Worte gefunden.
text <- readtext('data/complete_cws/out.txt')
worktext <- substr(text, 1, 861552)
# Der Korpus wird in die einzelnen Tokens unterteilt
tokens <- tokens(worktext)Es wird eine Dokument-Features-Matrix (dfm) erstellt, welche die Häufigkeit der einzelnen tokens beinhaltet. Die 25 häufigsten Worte werden aufgelistet und als Wortwolke dargestellt.
# Es wird einen Dokument-Features-Matrix erstellt (Dokument ist hier der gesamte Korpus und Features sind die Worte)
dfm <- dfm(tokens, tolower=TRUE)
dfm## Document-feature matrix of: 1 document, 5,750 features (0.00% sparse) and 0 docvars.
## features
## docs welcome register office rental network entrust find house call direct
## out.txt 94 47 1527 283 453 31 179 155 142 350
## [ reached max_nfeat ... 5,740 more features ]## [1] "office" "service" "building" "space"
## [5] "business" "contact" "entrepreneurship" "technology"
## [9] "innovation" "center" "community" "work"
## [13] "industry" "high" "district" "property"
## [17] "school" "management" "network" "enterprise"
## [21] "new" "development" "project" "time"
## [25] "room"
Bei der Selbstdarstellung von Coworking-Spaces liegt der Fokus demnach auf der Bereitstellung von Büroräumen und Dienstleistungen, wobei auch Aspekte wie Unternehmertum, Innovation und Technologie eine häufige Rolle spielen. Diese konzeptuelle Inhaltsanalyse basiert auf der Quantifizierung (durch Auszählung) von Begriffen und Inhalten. Zusätzlich zur konzeptuellen Analyse können mit einer relationalen Inhaltsanalyse die Beziehungen zwischen den Begriffen untersucht werden. Im Folgenden werden diese Strukturen anhand des gemeinsamen Auftretens bestimmt. Zu diesem Zweck wird zunächst eine sogenannte “Feature co-occurrence matrix” (fcm) erstellt.
#fcm <-
#tokens(worktext, remove_punct = TRUE) %>% tokens_tolower() %>%
#tokens_remove(stopwords("en"), padding = FALSE) %>% fcm(context = "window", window = 5, tri = FALSE)
fcm <- fcm (dfm)
fcm## Feature co-occurrence matrix of: 5,750 by 5,750 features.
## features
## features welcome register office rental network entrust find house call
## welcome 4371 4418 143538 26602 42582 2914 16826 14570 13348
## register 0 1081 71769 13301 21291 1457 8413 7285 6674
## office 0 0 1165101 432141 691731 47337 273333 236685 216834
## rental 0 0 0 39903 128199 8773 50657 43865 40186
## network 0 0 0 0 102378 14043 81087 70215 64326
## entrust 0 0 0 0 0 465 5549 4805 4402
## find 0 0 0 0 0 0 15931 27745 25418
## house 0 0 0 0 0 0 0 11935 22010
## call 0 0 0 0 0 0 0 0 10011
## direct 0 0 0 0 0 0 0 0 0
## features
## features direct
## welcome 32900
## register 16450
## office 534450
## rental 99050
## network 158550
## entrust 10850
## find 62650
## house 54250
## call 49700
## direct 61075
## [ reached max_feat ... 5,740 more features, reached max_nfeat ... 5,740 more features ]Die Matrix zeigt beispielsweise auf, dass “Office” häufiger gemeinsam mit “Network” auftritt (691731), als mit “Rental” (432141). Die folgende Darstellung zeigt die 20 häufigsten Worte aus der vorausgegangenen Wortwolke. Die Stärke der Verbindungslinien bezeichnet die Häufigkeit des gemeinsamen Auftretens.
## [1] "office" "service" "building" "space"
## [5] "business" "contact" "entrepreneurship" "technology"
## [9] "innovation" "center" "community" "work"
## [13] "industry" "high" "district" "property"
## [17] "school" "management" "network" "enterprise"
## [21] "new" "development" "project" "time"
## [25] "room"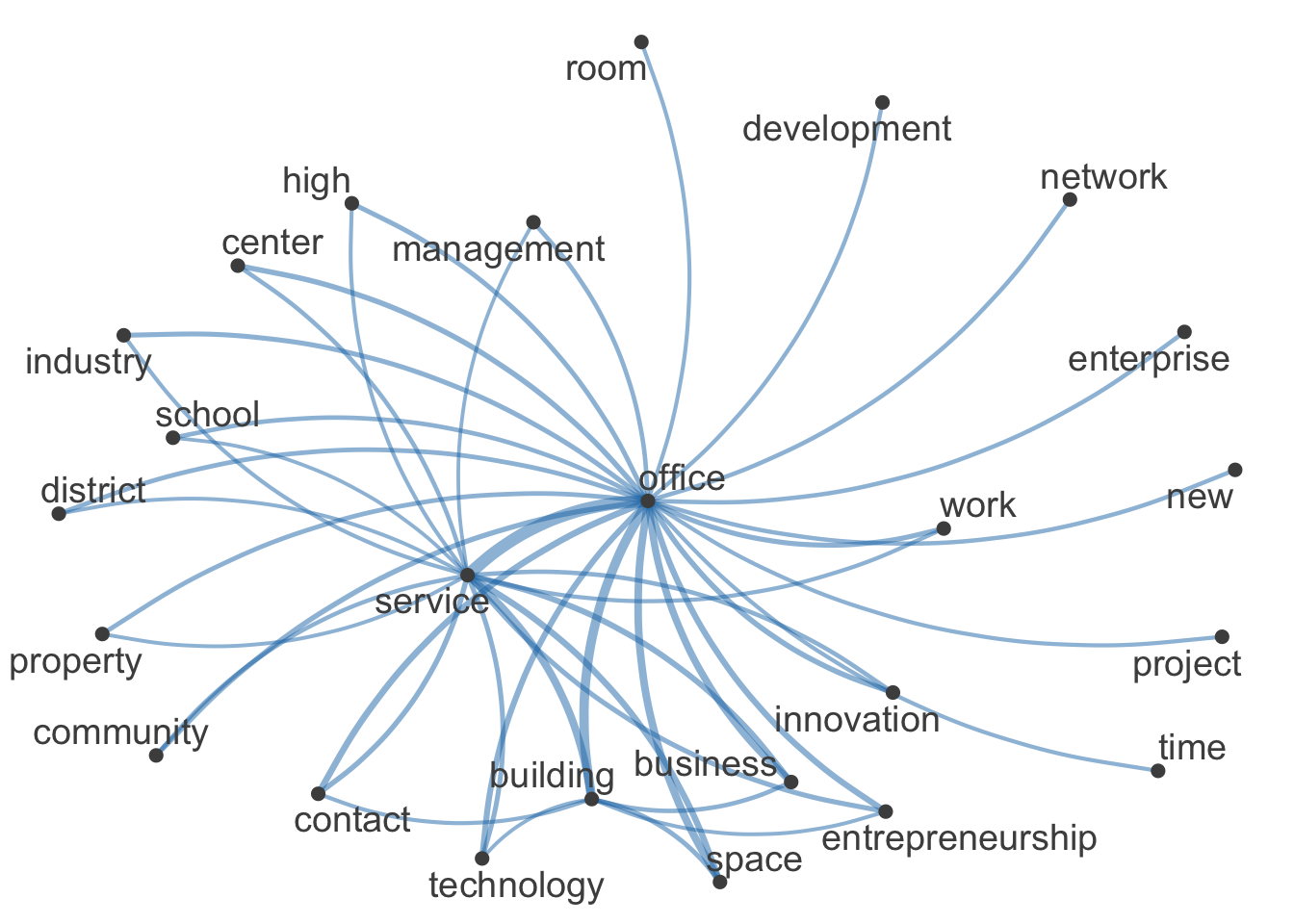
In vielen kommerziellen Anwendungen ist die Technik der “induktiven” Wortlistengenerierung implementiert. Dabei werden Worte gesucht und aufgenommen, sobald eine bestimmte Häufigkeit des Auftretens erreicht ist (zum Beispiel dreimaliges Auftreten beim kostenlosen CAT Scanner Tool, siehe http://www.catscanner.net). Validierte Wortlisten (Dictionaries), denen von Experten spezifische Skalen, Dimensionen oder Faktoren zugeordnet wurden, werden dann zur quantitativen Inhaltsanalyse eingesetzt.
Als weitere Form der relationalen Inhaltsanalyse können sogenannte Themen-Modelle (“topic-models”) bestimmt werden.
3.2.2 Themen-Modell
Bei der Themenanalyse werden spezifische semantische Strukturen gesucht, die sich aus der häufigen Verbindung von Worten ergeben können. Ein Überblick und Kurzbeschreibung dieser Verfahren in der Software R, findet sich z. B. auf hier: https://ladal.edu.au/topicmodels.html
Die heir folgende Themenanalyse basiert auf den Beschreibungen von 500 misslungenen Venture-Projekten aus dem Jahr 2016 auf der Plattform www.kickstarter.com
Kickstarter ist eine bekannte Crowdfunding-Plattform, die es Personen ermöglicht, ihre kreativen Projekte, Ideen oder Produkte vorzustellen und finanzielle Unterstützung von der breiten Öffentlichkeit zu erhalten. Auf Kickstarter können Kreative, Erfinder, Künstler, Musiker, Filmemacher und viele andere Personen Projekte starten und Geld von Unterstützern sammeln.
Die Funktionsweise von Kickstarter ist relativ einfach: Projektinitiatoren erstellen eine Projektseite, auf der sie ihr Vorhaben anhand von Möglichkeiten und Risiken beschreiben, Bilder oder Videos präsentieren und erklären, wie viel Geld sie benötigen und wofür sie es verwenden wollen. Unterstützer können dann Geld spenden, um das Projekt zu finanzieren, und oft erhalten sie im Gegenzug Belohnungen oder Anreize, je nach Höhe ihrer Spende.
reports <- read.csv("data/kickstarter/KickStarter_failed_projects_2016.csv", header=TRUE,sep=",")
reports <- reports [1:500,]
#reports[1]
# Korpus erstellen
risks <- reports [,c("full_no","risks")]
risks <- as.data.frame(risks)
korpus <- corpus(risks, docid_field = "full_no", text_field = "risks")
korpus.stats <- summary(korpus)
#korpus.stats
# tokens without numbers, punctuations, symbols, and stopwords
tokens <- tokens(korpus, remove_numbers = TRUE, remove_punct = TRUE, remove_symbols = TRUE)
tokens <- tokens_select(tokens, pattern = stopwords("en"), selection = "remove")
## Dokument-Feature-Matrix (DFM)
dfm <- dfm(tokens)
# Anzahl der Texte
ndoc(dfm)## [1] 500## [1] 5944#dfm
# Die Häufigsten Features (Types, unterschiedliche Worte) der DFM können bestimmt werden mit:
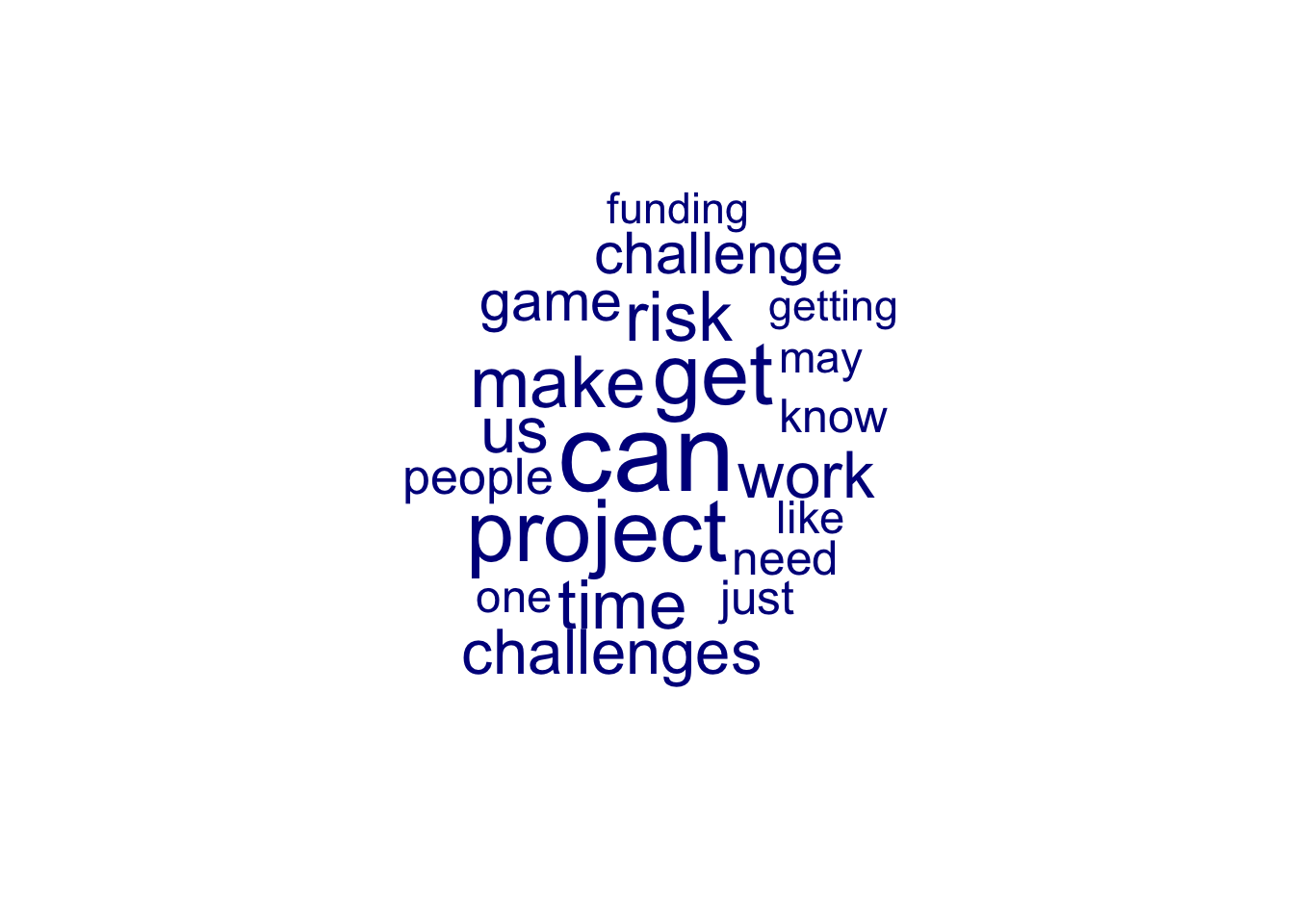
topfeatures(dfm, decreasing=TRUE)## project can time make challenges get us
## 244 208 159 137 132 130 119
## risk challenge work
## 116 114 114#head(dfm_sort(dfm, decreasing = TRUE, margin = "features"))
textplot_wordcloud(dfm, min_size = 0.5, max_size = 5, max_words = 60)
Hier sind die häufigsten Worte dargestellt, die als Risiken in Projekten, die später als gescheitert klassifiziert wurden, aufgezählt wurden.
Die Latent Dirichlet Allocation (LDA) ist ein generatives statistisches Modell, das Themen in einem Textkorpus identifiziert, ohne dass die Themen oder deren Anzahl im Voraus bekannt sind (Blei, 2003).
Es existieren verschiedene Kriterien, um die optimale Anzahl von Themen zu bestimmen (Griffiths & Steyvers, 2004). Im Folgenden werden vier verbreitete Metriken verwendet, und das Modell analysiert die Texte für jede einzelne Lösung. Im Beispiel beginnt der Code mit zwei Themen und endet bei 20 Themen.
if(!require("topicmodels")) install.packages("topicmodels")
if(!require("ldatuning")) install.packages("ldatuning")
library(topicmodels)
library(ldatuning)
topicmodels = convert (dfm, to= "topicmodels")
result <- FindTopicsNumber(
topicmodels,
topics = seq(from = 2, to = 20, by = 1),
metrics = c("Griffiths2004", "CaoJuan2009", "Arun2010", "Deveaud2014"),
method = "Gibbs",
control = list(seed = 77),
mc.cores = 2L,
verbose = TRUE
)## fit models... done.
## calculate metrics:
## Griffiths2004... done.
## CaoJuan2009... done.
## Arun2010... done.
## Deveaud2014... done.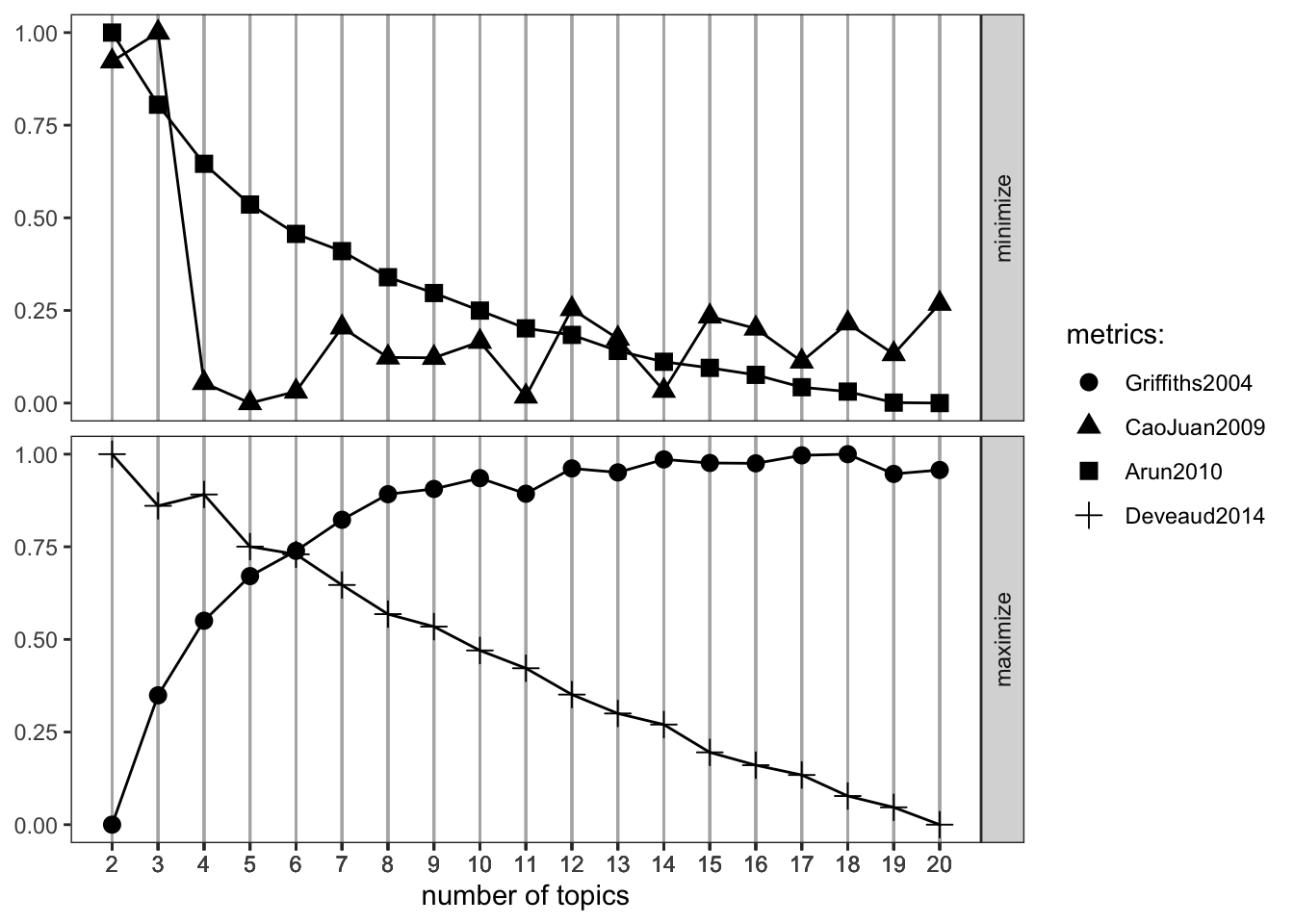
## A LDA_VEM topic model with 4 topics.## Topic 1 Topic 2 Topic 3 Topic 4
## 1 project project project can
## 2 challenges can time get
## 3 can also can project
## 4 get may make risk
## 5 help challenge us make
## 6 challenge la work time
## 7 need challenges new us
## 8 business map risk work
## 9 people time risks challenges
## 10 food space help game
## 11 one per production challenge
## 12 risks now challenges people
## 13 new already already just
## 14 able le may know
## 15 time die like need
## 16 many well film getting
## 17 make und however like
## 18 us use working one
## 19 funding risk one may
## 20 work make also able##
## 1 2 3 4
## 115 75 140 164Die Häufigkeitsverteilung der vier Themen ist relativ homogen. Basierend auf den enthaltenen Worten könnten sie wie folgt benannt werden:
Topic 1: Projektrisiken und Herausforderungen Dieses Thema könnte sich auf die verschiedenen Risiken und Herausforderungen beziehen, denen Kickstarter-Projekte gegenüberstehen, wie z.B. Zeitknappheit, finanzielle Engpässe, Arbeitsbelastung usw.
Topic 2: Finanzielle Risiken und Unsicherheiten
Dieses Thema könnte sich auf die finanziellen Aspekte der Kickstarter-Projekte konzentrieren, einschließlich der Möglichkeiten, Geld zu beschaffen, der Risiken, die mit der Finanzierung verbunden sind, und der Unsicherheiten in Bezug auf die finanzielle Machbarkeit.
Topic 3: Herausforderungen bei der Umsetzung
Dieses Thema könnte sich auf die spezifischen Herausforderungen bei der Umsetzung von Kickstarter-Projekten konzentrieren, wie z.B. technische Probleme, Produktionsprozesse oder rechtliche Hürden.
Topic 4: Risiken in der Projektentwicklung
Dieses Thema könnte sich auf die verschiedenen Risiken während der Projektentwicklung konzentrieren, wie z.B. Produktionsrisiken, rechtliche Risiken oder Risiken im Zusammenhang mit dem Projektmanagement.
Diese Benennungen erfassen die wesentlichen Aspekte, die in den jeweiligen Spalten vertreten sind, und bieten eine Vorstellung davon, worum es in jedem Thema geht. Die Wortwolken werden hier noch einmal für jedes Thema einzeln erstellt.
# jeweils 250 Worte der 4 Themen werden genutzt
topic_word_matrix <- terms(lda.modell,250)
topic_words <- as.data.frame(terms(lda.modell,250))
# Vier separate Frames für die Texte nach Themen
df1= as.data.frame(proportion)
df1$ID = row.names(df1)
df2= risks
head(df1)## Thema ID
## 2023_01_795 4 2023_01_795
## 2023_01_690 1 2023_01_690
## 2023_01_5346 1 2023_01_5346
## 2023_01_4240 3 2023_01_4240
## 2023_01_3667 3 2023_01_3667
## 2023_01_1557 3 2023_01_1557colnames(df2)<- c("ID", "Text")
df <- merge(df1,df2, by.x="ID")
topic1 <- subset( df, df$Thema==1)
topic2 <- subset( df, df$Thema==2)
topic3 <- subset( df, df$Thema==3)
topic4 <- subset( df, df$Thema==4)
topic1 <- topic1[-2]
topic2 <- topic2[-2]
topic3 <- topic3[-2]
topic4 <- topic4[-2]
token1 <- tokens(corpus(topic1, docid_field = "ID", text_field ="Text"), remove_numbers = TRUE, remove_punct = TRUE, remove_symbols = TRUE)
token1 <- tokens_select(token1, pattern = stopwords("en"), selection = "remove")
token2 <- tokens(corpus(topic2, docid_field = "ID", text_field ="Text"), remove_numbers = TRUE, remove_punct = TRUE, remove_symbols = TRUE)
token2 <- tokens_select(token2, pattern = stopwords("en"), selection = "remove")
token3 <- tokens(corpus(topic3, docid_field = "ID", text_field ="Text"), remove_numbers = TRUE, remove_punct = TRUE, remove_symbols = TRUE)
token3 <- tokens_select(token3, pattern = stopwords("en"), selection = "remove")
token4 <- tokens(corpus(topic4, docid_field = "ID", text_field ="Text"), remove_numbers = TRUE, remove_punct = TRUE, remove_symbols = TRUE)
token4 <- tokens_select(token4, pattern = stopwords("en"), selection = "remove")
## Dokument-Feature-Matrix (DFM)
# complete solution
dfm1 <- dfm(token1)
dfm2 <- dfm(token2)
dfm3 <- dfm(token3)
dfm4 <- dfm(token4)
textplot_wordcloud(dfm1, min_size = 0.5, max_size = 5, max_words = 20)


Weitere Informationen können aus dem gemeinsamen Auftreten der Worte (“co-occurrence”) gewonnen werden, wobei die Stärke der Verbindungen in der folgenden Abbildung eine höhere “co-occurrence” indiziert. Der Code ist hier nur für das erste Thema ausgeführt.
fcm <-
tokens(token1, remove_punct = TRUE) %>% tokens_tolower() %>%
tokens_remove(stopwords("en"), padding = FALSE) %>% fcm(context = "window", window = 5, tri = FALSE)
set.seed(100)
textplot_network(fcm_select(fcm, topfeats), min_freq = .5)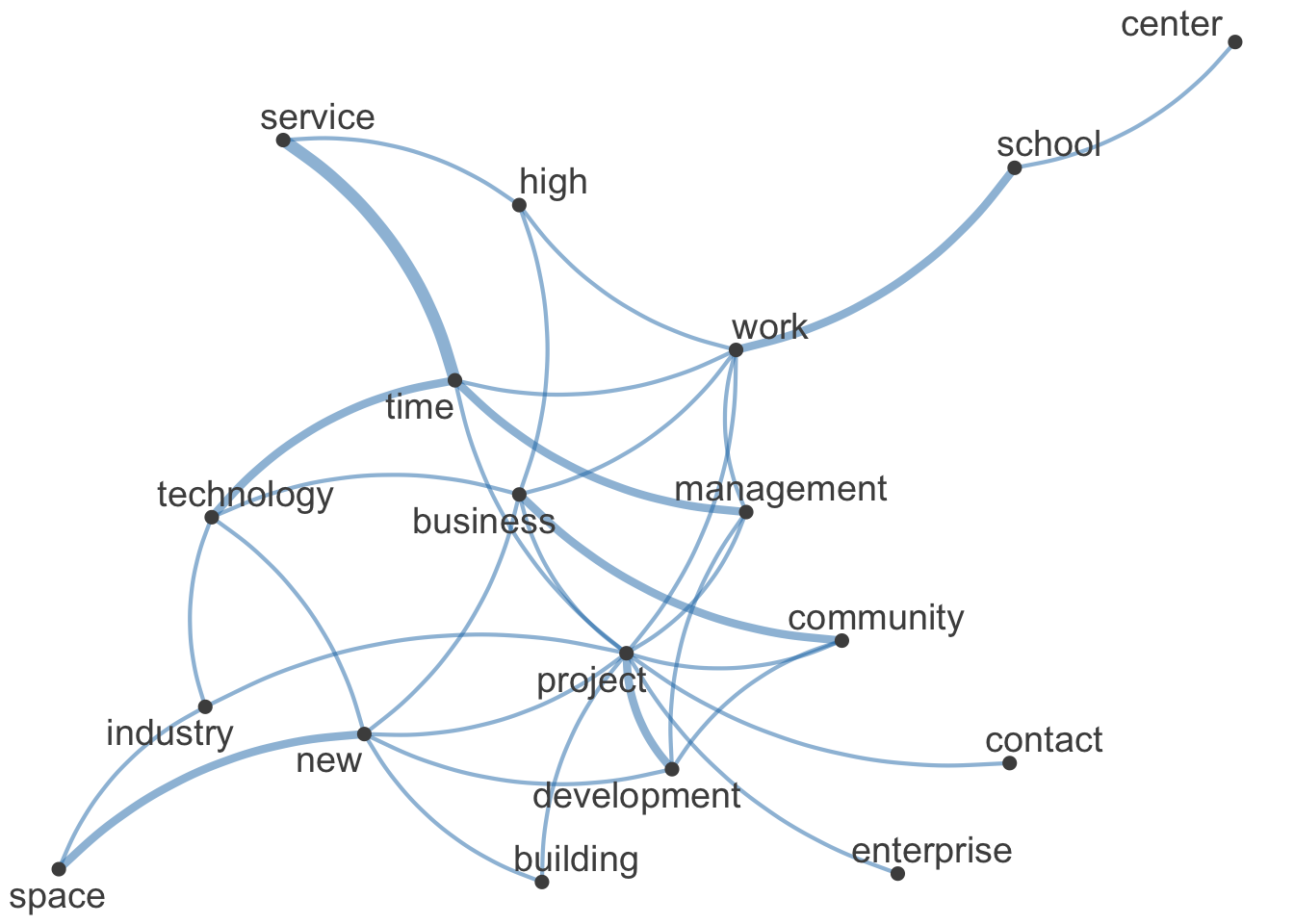
Neben solchen induktiven Inhaltsanalysen werden zunehmend validierte Dictionaries (Keyword-Listen) für verschiedene Konzepte angeboten und eingesetzt. Einen Überblick bietet die Homepage der Software CAT Scanner [http://www.catscanner.net].
So beschreiben Kindermann et al. (2020) eine inhaltsbasierte Messung von Digitaler Orientierung im unternehmensstrategischen Kontext. Die relative Häufigkeit des Auftretens von Schlüsselworten indiziert die Ausprägung digitaler Ausrichtung in vier Dimensionen (Digital Technology Scope, Digital Capabilities, Digital Ecosystem Coordination, Digital Architecture Configuration). Die Autoren haben eine Validierung des Konstrukts (bzw. seiner Messung) anhand der Entrepreneurial Orientation Operationalisierung von Mckenny (2016) durchgeführt.
Eigene Untersuchungen zeigen positive Korrelationen von Digitaler Orientierung und Entrepreneurship Orientierung (Mckenny, 2016) (r = .23, p < 0.001), am stärksten mit Innovativität, einer Dimension der Entrepreneurial Orientation (r = 0.26, p < 0.001). Andererseits sehen die Autoren auch diskriminante Validität als gegeben an, weil die Korrelation den Wert von 0.50 nicht überschreitet (Kindermann et al., 2020).

3.3 Gioia’s Methodologie
In seinem Artikel “Seeking Qualitative Rigor in Inductive Research: Notes on the Gioia Methodology” beschreiben Gioia und seine Kollegen eine Vorgehensweise, die als Ansatz zur Sicherung der Qualität induktiver Forschung dienen kann, bekannt als die “Gioia-Methodologie”. Das Vorgehen basiert auf zwei fundamentalen Grundannahmen (Gioia, Corley & Hamilton, 2013): 1) die organisationale Welt ist sozial konstruiert und 2) die Menschen sind wissentlich Handelnde (“knowledgable agents”), d.h. sie haben Ziele, alle notwendigen Informationen und erklären ihre Kognitionen, Intentionen und Handlungen rational.
Die Aufgabe des Forschers besteht darin, die Erfahrungen und Interpretationen der Befragten in erster Linie zu berichten. In der unvoreingenommenen Darstellung besteht nach Gioia et al. (2013) die Möglichkeit, tatsächlich neue Konzepte zu entdecken und nicht nur die bestehenden Konzepte zu bestätigen.
Dies erfordert eine zeitaufwendige Auseinandersetzung mit den vorliegenden und oft umfangreichen Daten. In den ersten Runden der Analyse sollten die Kategorien als Begrifflichkeiten der Befragten belassen werden, was schon bei 10 Interviews zu einer hohen Anzahl (50-100) von Kategorien “erster Ordnung” führen kann. In einem zirkulären Prozess untersucht der Forschende dann Ähnlichkeiten und Unterschiede in diesen Kategorien, um relevante Kategorien zu identifizieren und ihre Anzahl zu reduzieren. In dieser Phase des Prozeses werden die Kategorien benannt und umschrieben. Es geht darum, die Gestalt oder Struktur in der Anordnung der Kategorien zu finden und es steht die Frage im Vordergrund, um welche Bedeutung und welche Themen es bei diesen Begriffen und Kategorien erster Ordnung geht.
Während die Kategorien erster Ordnung also die Realität der Befragten mit deren eigenen Worten darstellten, repräsentieren die Themen (Kategorien zweiter Ordnung) die Interpretationen und Abstraktionen dieses Materials durch den Forschenden.
Bei der weiteren Analyse dieser Themen geht es um die Frage, ob diese Themen Konzepte offenbaren, die geeignet sind, um die Beobachtungen zu beschreiben und zu erklären. Während einige Konzepte (z.B. Werte, Strategien oder Legitimationen) in ihrer Relevanz etabliert und offensichtlich scheinen werden, sind diejenigen von besonderem Interesse, die einen Neuigkeitsgehalt aufweisen.
Beispielsweise führte Herzberg & Snyderman (1959) in den 50er Jahren des letzten Jahrhunderts Interviews mit Arbeitnehmern. Entgegen der verbreiteten Vorstellung von Eindimensionalität der Arbeitszufriedenheit, also der Annahme, dass die Arbeitszufriedenheit und -unzufriedenheit zwei Seiten derselben Medallie sind und sich daher gegenseitig ausschließen, fand Herzberg Themen, die entweder nur zufrieden oder nur unzufrieden machten.
Wenn der Forschende ein praktikables Set an Themen und Konzepten gefunden hat, dass die Berichte der Befragten umfassend widerspegelt und die Daten dem Forschenden keine weiteren Informationen ermöglichen, wird die Phase der Interpretation als abgeschlossen angesehen. Dieser Zeitpunkt wird als “theoretische Sättigung” bezeichnet (Glaser & Strauss, 1967).
So fand Herzberg & Snyderman (1959) in den Interviews Hinweise darauf, dass zwei voneinander unabhängige Dimensionen der Zufriedenheit unterschieden werden können. Die daraus abgeleitete Zwei-Faktoren-Theorie der Arbeitsmotivation und -zufriedenheit hatte lange Zeit einen starken Einfluss auf das Verständnis von Arbeitsmotivation und -zufriedenheit in Unternehmen und in der Organisationspsychologie.
Nach Gioia et al. (2013) können die vorgefundenen Themen und Konzepte in einem abschließenden Schritt übergeordneten Dimensionen zugeordnet und die resultierende Datenstruktur sollte wie folgt dargestellt werden:
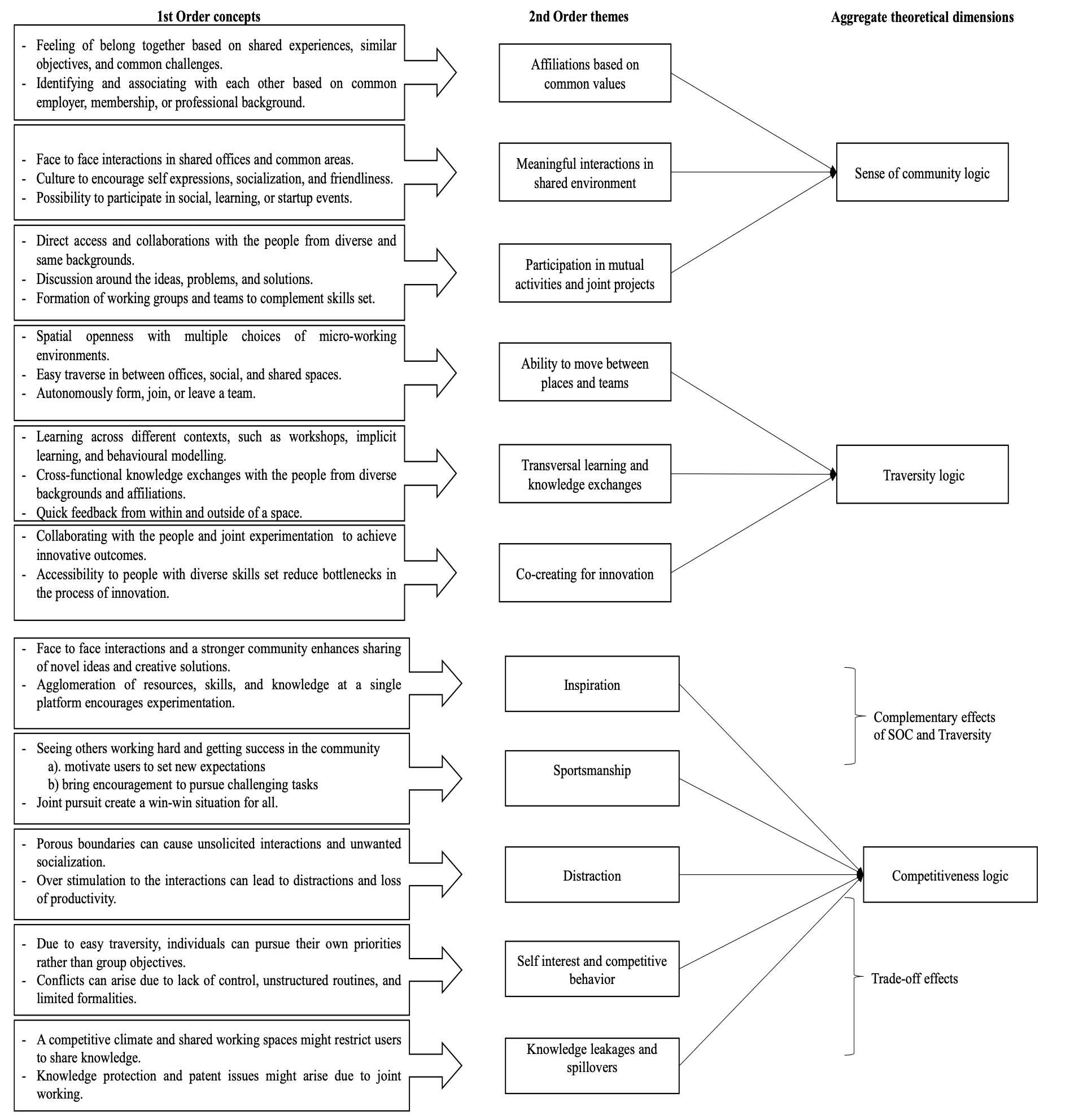
Um die Konsistenz und Validität der Ergebnisse zu gewährleisten und zu überprüfen, betonen Gioia et al. (2013) die Notwendigkeit einer sorgfältigen Dokumentation bei der Datenverarbeitung, der Kategorienbildung sowie der Themen-Identifizierung und eine sorgfältige Interpretation der Ergebnisse durch mehrere unabhängige Kodierer.
3.4 Quantitatives
Im Umgang mit der Subjektivität der Forschenden besteht ein zentrales Problem der Forschung. Da Forschende oft selbst Teil der Gesellschaft sind, die sie untersuchen, neigen sie dazu, eine spezifische Perspektive zu vertreten, Aspekte zu übersehen und persönliche Vorurteile in den Forschungsprozess einzubringen (Baur & Blasius, 2022).
Dies zeigt sich z.B als Hindernis beim Lesen und Verstehen wissenschaftlicher Texte, wenn erkannt wird, “dass wir nicht verstehen, was ein Autor ausdrücken will [oder] dass der Autor von verschiedenen Lesern unterschiedlich verstanden wird” (Westermann, 2000, S. 66).
Diese Schwierigkeiten können unterschiedliche Ursachen haben. Einige entstehen durch die Sprache und die Art der Darstellung im Text. Diese können durch klarere Sätze, zusätzliche Erklärungen oder Beispiele reduziert werden. Andere Schwierigkeiten entstehen durch die Komplexität der Themen (Ross, 1977). Sie können überwunden werden, indem man sich intensiv mit dem Text auseinandersetzt, sich Vorkenntnisse aneignet oder andere Quellen liest.
Einige Verständigungsprobleme in der wissenschaftlichen Kommunikation bleiben jedoch oft unbemerkt und sind schwerer zu beheben. Diese Probleme haben oft mit methodischen Mängeln zu tun. Einige Beispiele dafür sind Unklarheiten über die Art und den Bezug von Aussagen, Schwierigkeiten bei der argumentativen Verknüpfung von Aussagen sowie Unsicherheiten über die Bedeutung und Verwendung von Begriffen (Westermann, 2000).
In der quantitative Forschung versucht man diesen Formen von Subjektivität in Annahmen, der Wahrnehmungen und den Aussagen durch eine grundlegende rationale Struktur entgegen zu wirken. So kann bspw. der Begriff der Identität einem unterschiedlichen Verständniss unterliegen und es ist in wissenschaftlichen Arbeiten erforderlich, solche Unklarheiten zu reduzieren bzw. zu vermeiden.
“A good definition provides necessary and sufficient conditions for classifying any empirical referent as either an instance of the term or not. If a term is undefined, the author must assume that potential readers already agree on its meaning – often a dangerous presumption in light of our natural.” (Markovsky & Frederick, 2020, S. 169)
Gute Definitionen sind daher entscheidend, um empirische Beobachtungen richtig zu kategorisieren - sie stellen die notwendigen und ausreichenden Bedingungen dafür dar. Besonders wenn ein Begriff spezifisch (z.B. “venture founding motive divergence”) oder komplex (z.B. “identity”) ist und nicht definiert wurde, ist es unwahrscheinlicher, dass eine gegenseitige Übereinstimmung besteht (Markovsky & Frederick, 2020; Ross, 1977).
Wenn Markovsky & Frederick (2020, S. 175) Identität als “rollenbezogene Selbstwahrnehmungen” definiert, müssen sie zuerst den Begriff “Rolle” definieren, der wiederum mit dem Konzept der “Sozialen Position” verbunden ist, und so weiter.
Zusammenfassend sollten Begriffe in wissenschaftlichen Arbeiten klar definiert werden, und die Annahmen über Zusammenhänge (Hypothesen) sollten in formale Sprache und Konditionalsätze umgewandelt werden können (Westermann, 2000, S. 190).
3.5 Datenqualität
Jede empirische Ableitung, Analyse oder Aussage kann nur so gut sein, wie es die Qualität der Daten zulässt. Der Ausdruck “Garbage In, Garbage Out” (GIGO) aus dem Bereich der Informatik betont die Bedeutung der Qualität der Eingabedaten für die Genauigkeit und Zuverlässigkeit der Analyse von Systemen. Der Kerngedanke dabei ist, dass fehlerhafte oder ungenaue Eingabedaten zwangsläufig zu fehlerhaften oder ungenauen Ergebnissen führen werden, unabhängig von der Qualität des Systems oder des Algorithmus.
Traditionell legt die Wissenschaft Kriterien zur Bewertung der Datenqualität fest, die auf der Wahrscheinlichkeitstheorie basieren und sich als nützlich erwiesen haben (Bouncken, 2018). Eine häufig verwendete Definition für Datenqualität bezieht sich auf die Eignung der Daten für den beabsichtigten Verwendungszweck (Strong, Lee & Wang, 1997; Treiblmaier, 2011).
Je nach Forschungsziel können die Anforderungen an die Datenqualität variieren, sei es, um Phänomene zu erfassen, ihr Auftreten zu beschreiben oder Zusammenhänge nachzuweisen. Zum Beispiel erfordert die statistische Generalisierung auf eine Grundgesamtheit die Auswahl einer repräsentativen Stichprobe, die die Merkmale der Grundgesamtheit widerspiegelt und die Wahrscheinlichkeit der Auswahl für jedes Mitglied bestimmt werden kann (Baker et al., 2013, S. 77). Dies entspricht der traditionellen Definition von Repräsentativität.
In der empirischen Forschung werden Gütekriterien beschrieben, anhand derer die Qualität der Daten und der daraus ableitbaren Entscheidungen bewertet werden. Die Berücksichtigung dieser Faktoren trägt dazu bei, die Qualität der Forschung zu gewährleisten und sicherzustellen, dass die erhobenen Daten und abgeleitete Aussagen zuverlässig sind und den Forschungszielen entsprechen.
3.5.1 Objektivität
Die Objektivität wird als ein zentrales Kriterium wissenschaftlicher Praxis angesehen und basiert auf dem grundlegenden Prinzip der Unabhängigkeit und Replizierbarkeit. Ereignisse oder Merkmale, um die es in dem Forschungsthema geht, sollen also unabhängig vom Forscher erfasst werden können und einer wiederholten Überprüfung standhalten, um die Integrität und Glaubwürdigkeit wissenschaftlicher Forschung und Erkenntnisse zu gewährleisten.
Neutralität und Unvoreingenommenheit bei der Datenerhebung kann zum Beispiel durch Interessenkonflikte beeinträchtigt werden, soweit sie nicht transparent offengelegt werden. So ist die Finanzierung von wissenschaftlicher Forschung oft begrenzt und erfordert die Priorisierung von Ressourcen. Forschungsinstitutionen, Förderorganisationen und Regierungen müssen dabei Entscheidungen treffen, wie sie begrenzte Mittel einsetzen.
Darüber hinaus stellt Objektivität den Inhalt von Beobachtungen, als grundlegende Form der Datenerhebung, auch in ein Verhältnis zu dem begrenzten Wahrnehmungsvermögen des Beobachters, also den eingesetzten Sinnesorganen und technischen Hilfsmitteln, mit denen beobachtet wird.
Im empirischen Kontext wird die Objektivität von Beobachtungen oder Bewertungen durch die Beobachterübereinstimmung in Form mathematischer Koeffizienten berichtet. Je höher der Beobachterübereinstimmungs-Koeffizient, desto größer ist die Konsistenz zwischen unabhängigen Beobachtern und desto zuverlässiger sind deren Beobachtungen oder Bewertungen (vgl. Gioia’s Methodologie).
Hoch strukturierte quantitative Befragungen (Surveys) werden im Allgemeinen im Gegensatz zu unstrukturierten qualitativen Interviews als objektiver angesehen. Das liegt hauptsächlich an der standardisierten Natur von Umfragen, die es ermöglicht, Daten auf eine konsistente und vergleichbare Weise zu sammeln und zu analysieren.
Obwohl strukturierte Umfragen als objektiver angesehen werden, bieten qualitative Interviews dennoch wichtige Einblicke und ergänzen quantitative Ansätze. Sie ermöglichen eine tiefere Exploration von Themen und ein besseres Verständnis der Motivationen und Perspektiven der Teilnehmer. Letztendlich hängt die Wahl zwischen quantitativen Umfragen und qualitativen Interviews von den spezifischen Forschungszielen, der Natur der Fragestellung und den verfügbaren Ressourcen ab.
3.5.2 Validität
Validität bezeichnet die Eignung, Fähigkeit oder Gültigkeit richtiger Entscheidungen. Die Entscheidungen können sich dabei auf das Forschungsdesign, die Methoden, die Messungen oder die Bewertungen beziehen. Im Kontext der Datenerhebung und Messung ist die Validität beispielsweise ein zentrales Konzept um sicherzustellen, dass tatsächlich das gemessen wird, was beabsichtigt war. Somit ist eine sorgfältige Auswahl der Messinstrumente und die Überprüfung ihrer Validität sind entscheidend für die Validität der Datenerhebung.
Soll z.B. das Konstrukt “Innovation” gemessen werden, gibt die Inhaltsvalidität darüber Auskunft, ob die Messung alle relevanten Aspekte von Innovation abdeckt. Die Konstruktvalidität hingegen gibt eine Bewertung darüber, ob die Messung das zugrunde liegende Konstrukt genau erfasst.
Als Kriteriumsvalidität bezeichnet man die Gültigkeit der Messung in Bezug auf ein externes Kriterium, dessen Zusammenhang mit Innovation als gültig akzeptiert wird.
Die interne Validität (auch als “Validität der ceteris-paribus-Bedingung”) bezeichnet die Tatsache, dass unterschiedliche Konsequenzen (bzw. Ausprägungen einer abhängigen Variable) nur auf unterschiedliche Ursachen (Ausprägungen einer unabhängigen Variable) zurückgeführt werden können. “Das empirische Ergebnis einer intern validen Untersuchung ist also eindeutig kausal interpretierbar” (Westermann, 2000, S. 303). Damit beinträchtigen alle Störvariablen die interne Validität.
Die externe Validität gibt darüber Auskunft, in wie fern die Messung oder ein Ergebnis auf andere Situationen oder Populationen übertragen, also verallgemeinert werden kann. Die externe Validität eines Ergebnisses ist zum Beispiel eingeschränkt, wenn es nur in einer Stichprobe auftritt und nicht in der Gesamtpopulation repliziert werden kann (Westermann, 2000, S. 431).
3.5.3 Reliabilität
Das Kriterium der Reliabilität bezieht sich auf die Genauigkeit, im Sinne der Konsistenz und Stabilität, mit der sich Ereignissen, Eigenschaften oder Merkmalen mit Hilfe eines Messinstrumentes in einer Datenerhebung Zahlenwerte zuordnen lassen. Reliable Messinstrumente sollten zu sehr ähnlichen Werten führen, wenn sie demgleichen Objekt unter denselben Bedingungen wiederholt einen numerischen Wert zuweisen.
Im Allgemeinen ist die Reliabilität um so höher:
- je geringer das Ergebnis der Messung vom Einfluss des Forschers abhängt
- je geringer das Ergebnis der Messung vom Einfluss des gemessenen Objektes abhängt
- je höher die Äquivalenz (Gleichwertigkeit) von Ergebnissen ist, die das Gleiche messen
Zur Beurteilung der Reliabilität wird traditionell der Koeffizient \(\alpha\) verwendet (Cronbach, 1951).
Cronbach (1951) selbst bezeichnet \(\alpha\) als “coefficient of equivalence”, was er von der Genauigkeit im Sinne des “coefficient of precision” abgrenzt. Demnach beurteilt \(\alpha\) die Gleichwertigkeit von Messungen und nicht deren Genauigkeit im Sinne geringer Einfüsse durch den Forscher oder das zu messende Objekt.
Bei \(\alpha\) oder anderen “coefficient of equivalence” wird die Übereinstimmung zweier Messmethoden in Bezug auf das gleiche Objektes bestimmt. Solche Koeffizienten werden z.B. eingesetzt, um die Objektivität von Beobachtungen (Beobachterübereinstimmungs-Koeffizienten), die Objektivität von Auskunft gebenden (“Inter-Rater-Reliabilität”), oder der Auswahl von Befragungs-Items für ein Thema (“Inter-Item-Reliabilität”).
Werden zum Beispiel Mitarbeitern 10 Fragen zur Arbeitszufriedenheit vorgelegt und die Antworten weisen eine hohe individuelle Übereinstimmung auf, dann wäre die Antwort auf eine spezifische Frage equivalent zu den Antworten auf die anderen Fragen. Ist die Übereinstimmung der 10 Antworten hingegen gering, beinhalten die Antworten Ungenauigkeiten in Form systematischer oder unsystematischer Messfehler.
Der “coefficient of precision” im Sinne von Cronbach (1951) eine wiederholte Messung desgleichen Objektes mit dem gleichen Instrument. Abweichungen werden in diesem Fall als Bestandteil des zu messenden Merkmals angesehen.
3.5.4 Repräsentativität
Repräsentativität ist ein zentrales aber nicht unumstrittenes Konzept zur Bewertung von Umfragen, Ergebnissen und Aussagen. In der mathematischen Statistik, so formuliert es Schnell (2018), sind unklare Begriffe wie “Repräsentativität” unnötig bzw. es gibt sie gar nicht.
In der traditionellen Definition von Repräsentativität ist es erforderlich, einer repräsentative Stichprobe auszuwählen, um die Ergebnisse einer Umfrage auf die Grundgesamtheit zu verallgemeinern bzw. zu übertragen.
Eine Stichprobe wird als repräsentativ angesehen, wenn sie die Merkmale der Grundgesamtheit widerspiegelt und die Wahrscheinlichkeit der Auswahl für jedes Mitglied bestimmt werden kann (Baker et al., 2013, S. 77).Eine solche Auswahl der Stichprobe basiert auf dem Konzept des Zufalls, wonach ein Ereignis oder eine Situation, durch keinen erkennbaren oder vorherbestimmten Ursache-Wirkungs-Zusammenhang bestimmt ist (Griessl, 2023).
Der Norweger Anders Nicolai Kiær hatte diese Situation als erster auf die Auswahl von Teilnehmern in Befragungen übertragen. Nach seinem Ansatz, den er 1895 als repräsentative Methode vorstellte, sei es nicht notwendig, die gesamte Bevölkerung zu befragen, sondern es würde ausreichen, eine bestimmte Anzahl von (etwa 1000) zufällig ausgewählten Personen zu befragen.
Repräsentativität bezieht sich also, wo immer der Begriff verwendet wird, auf die Frage “Repräsentativ wofür?”. Eine differenzierte Beschreibung der Stichprobenelemente beschreibt demnach auch immer den spezifischen Teil der Population, den sie repräsentiert.
3.6 Befragung
Qualitative und quantitative Befragungen sind derzeit Standardinstrumente unserer Forschung. Qualitative Befragungen, wie Interviews, können entweder gar nicht oder teilweise strukturiert sein und gewähren dem Befragten weitgehend Freiheit bezüglich des Inhaltes seiner Antwort.
Im Zusammenhang mit Coworking-Spaces haben wir 2016 einige Interviews geführt, um der Frage nachzugehen, durch welche räumlichen Bedingungen diese Räume beschrieben werden können.
Im Folgenden sind Beispiele aus drei Interviews aufgeführt. Es ist jeweils die Antwort auf die Aufforderung: “Bitte beschreibe deinen coworking space im Sinne von Ausstattung, dem Design und den Services, die ihr euren Nutzern anbietet!”.
Interview 1:
Ich kann dich auf jeden Fall herumführen. Tatsächlich, okay, also das hier ist die Küche. Das hier ist der Chill-Out-Bereich. Und hier, wie du siehst, der Tisch aus Zinn. Hier haben wir noch andere Dinge. Und hier sind einige Arbeitskollegen (lachend). Und dann haben wir hier einen Besprechungsraum - also hier ist ein Besprechungsraum. Und hier haben wir Stehpulte. Wir haben noch eine Etage unten. Und ja, unten ist mehr so (unv.). Und dann haben wir unten fest installierte Schreibtische, etwa zehn Tische dort unten.
Interview 2: Okay, also ja, wir befinden uns auf ungefähr achthundertsechzig Quadratmetern in einem Gebäude, das ungefähr dreißig Jahre lang leer stand. Es ist ein altes Theater, das zuvor eine Autohändler, ein Bürogebäude, ein Radiosender, eine Kirche und dann dreißig Jahre lang leerstand. Als wir mit dem Projekt begannen, wuchsen Bäume im Inneren des Gebäudes, und es war an jeder Oberfläche von Schimmel bedeckt. Jetzt hat es also mit uns ein neues Leben bekommen. Wir sind auch im Gebäude mit einem Werkstattbereich, der sich auf Schmuck konzentriert, einem Satz Büros, die alle Partner für Gemeindeentwicklung sind, einer Videospielfirma und zwei Universitätsfilmprogrammen. Es ist also ein ziemlich großes Gebäude, das sich über einen ganzen Block erstreckt, und wir sind im vorderen Teil davon, an der Ladenfront. Unsere Lage in der Stadt ist wichtig zu beschreiben. Wir befinden uns direkt an der Kreuzung von [Adresse], was in der Stadt die Grenze zwischen Ost und West sowie zwischen Nord und Süd darstellt. Das spielt auf vielfältige Weise eine Rolle, da die Stadt sehr auf Territorium ausgerichtet ist und es uns ermöglicht, unglaublich neutral zu sein. Das betrifft nicht nur gemeinnützige Organisationen und Unternehmen, sondern auch Stiftungen sind oft mit einem bestimmten Viertel oder Gebiet verbunden. Außerdem sind wir in einem Künstlerviertel, einem von drei in der Stadt, also in der Nachbarschaft passieren viele kreative Dinge. Wir haben auch einen der besseren Zugänge zum öffentlichen Nahverkehr in dieser Stadt. Die Stadt hat kein großartiges öffentliches Verkehrssystem, aber wir sind in der Nähe des Regionalbahnhofs, der einzigen Straßenbahnlinie und einer Vielzahl von Radwegen und Buslinien. So haben wir uns also für diese Lage entschieden. Im Inneren gibt es eine Mischung aus privaten Büros mit vierzehn privaten Büros und zwei großen offenen Co-Working-Bereichen, die wir auch als Veranstaltungsräume nutzen. Es ist irgendwie wie ein “U” geformt. Auf der linken und rechten Seite des “U” befinden sich unsere offenen Bereiche, und im hinteren Teil befindet sich eine Art ruhiger, konzentrierter Büroraum, sowie ein zusätzlicher Co-Working-Bereich. Darüber hinaus haben wir einen Konferenzraum und drei kleine Besprechungsräume und zwei Telefonkabinen. Das ist unser Raum.
Interview 3:
Mhm (bejahend). Ich würde gerne damit starten, dass wir kein klassischer Coworking-Space sind. Das heißt, dass wir uns nicht als Coworking-Space im herkömmlichen Sinne verstehen, wo sich mehrere Leute zusammentun, um einen Raum zu nutzen. Wir verstehen uns tatsächlich eher als Co-Creation-Space oder als Rahmen und Impulsgeber für Menschen, die kooperativ arbeiten wollen und gleichzeitig an einem zweiten, verbindenden, inhaltlichen Element interessiert sind, das sich rund um das Thema “Enkeltaugliches Wirtschaften” dreht. Also, das kennt man als Social Business, Social Entrepreneurship und so weiter. Da gibt es ganz verschiedene Begriffe, die wir zusammenfassend mit enkeltauglichem Wirtschaften meinen. Das sind also die zwei Säulen, auf denen sich der ganze Angebotsfächer bezieht. Und eine Dimension davon ist der Raum. Wir haben hier ungefähr achthundertfünfzig Quadratmeter mit Meetingräumen, Telefonkabinen, die auch vor allem die wichtige Funktion haben, sozusagen ein Rückzugsort zu sein, weil Coworking an sich etwas ist, wo man nie einen ganz ruhigen Platz oder Ort findet. Und praktisch diese Kabinen auch dazu dienen, sich komplett zurückzuziehen. Wir haben so etwas wie einen Marktplatz, das heißt, das ist dieser Coworking-Bereich, wo man sehr stark ins Netzwerken gehen kann, wo man sich auch hinsetzt und damit signalisiert: “Ja, du kannst mich auch jederzeit ansprechen.” Gleichzeitig auch die Galerien, Coworking-Flächen, die sozusagen eher zum Fokussieren und zum Arbeiten gedacht sind. Das heißt nicht, dass man sich gar nicht ansprechen kann, aber dass man damit signalisiert: “Ich bin sozusagen gerade konsequent in einer Arbeit.” Nutzen viele von denen auch, die sozusagen einen regelmäßigen Sitzplatz und ihren Arbeitsschwerpunkt tatsächlich ins Hub verlegt haben. Wir haben eine große Veranstaltungsfläche, einen Workshopraum, eine Teeküche, Drucker, Internet und alles, was es dazu braucht, um gut arbeiten zu können. Und was vielleicht so eine Spezialität hier auch ist, ist, dass wir rund um die Coworking-Flächen, die haben sozusagen einen unteren Bereich, lauter kleine Büros haben, die alle voll verglast zur Coworking-Fläche sind, damit eben der Transparenzgedanke sich auch durchzieht und man sich gegenseitig erleben kann, dass man auch eher mit offenen als mit geschlossenen Türen arbeitet, wobei das natürlich auch jedem freigestellt ist. Die Büros sind dazu da, dass Teams ab vier Personen einen zusätzlichen Rückzugsort haben können. Die sind fest vermietet, wie gesagt, ab vier Personen, haben wir in unterschiedlichen Größen. Von der Gestaltung, weil das ja auch ein Teil der Frage war, folgt generell die CWS-Philosophie dem gezielten Unperfektem, also Improvisation auf hohem Niveau oder so ähnlich könnte man es nennen. Das heißt also, zu verstehen, dass Innovationsräume oder Räume, die zur Innovation einladen sollen, zu Kreativität, zum Neudenken, zum Über-Zukunft-Nachdenken, auch in einem enkeltauglichen Sinn, nicht die Perfektion brauchen, wie man das oft von größeren Unternehmen kennt, das heißt oft durch weiß mattierte Oberflächen und so weiter, in Steelcase-Möbel ausgedrückt, sondern man gezielt unperfekt unterwegs ist, also eher einen Werkstattcharakter schafft, weil es darum geht, Experimente zu fahren und es darum geht, sich mit dem Raum zu identifizieren, mit der Umgebung zu identifizieren. Und das fällt natürlich leichter, wenn ich Anknüpfungspunkte habe, wo ich zum Beispiel sofort über Verbesserungsmöglichkeiten nachdenke, wo ich gleichzeitig aber auch die gestalterische Qualität habe, zu sehen, in welchem Detailgrad das eben auch die Gestalter in der Lage waren zu gestalten, also damit zu spielen, dass es teilweise sozusagen sehr bewusst bis ins Detail durchgestaltet ist und teilweise sehr roh, zum Beispiel die ganzen Rohre an der Decke. Das heißt, wenn hier im Haus jemand die Waschmaschine laufen lässt, dann hören wir, wenn das Wasser sozusagen herunterläuft. Das ist die eine Dimension. Die zweite Dimension ist, dass wir mit viel Eigenleistung den ganzen CWS aufgebaut haben. Auf der einen Seite sicherlich auch ein Kostenpunkt, vor allem aber wieder auch der Identifikationspunkt. Das heißt, wir haben in vielen Bereichen versucht, so früh wie möglich die Menschen, die hier drinnen arbeiten wollen, mit einzubinden in die Entstehungsphase. […]
Wie erwartet variieren die Antworten in Bezug auf Umfang und Inhalt je nach Interpretation und Reaktion des Befragten. Selbst bei einer identischen Eingangsfrage sind die inhaltlichen Unterschiede zwischen den Interviews deutlich und die Auswertung solcher Transkripte ist stark subjektiv geprägt. Die Verwendung von Textanalysen wurde bereits erwähnt, um die Häufigkeit bestimmter Wortwahl oder Themen zu quantifizieren.