Kapitel 3 Datenerhebung
Die Erhebung von Daten ist ein essenzieller Bestandteil in jeder empirischen Untersuchung. Eine Datenerhebung wird als objektiv angesehen, wenn sie das betreffende Thema bzw. Merkmal unabhängig vom Forscher erfasst. Die Objektivität ist damit eines der drei zentralen Gütekriterien von Datenerhebungen in der empirischen Forschung.
Auf Grund ihrer hohen Verbreitung als Datenerhebungsverfahren soll im Folgenden auf die Beobachtung, die Befragung im Interview und mit einem Fragebogen eingegangen werden. Alle drei Datenerhebungsverfahren können sowohl in qualitativer als auch in quantitativen Varianten eingesetzt werden.
Die Datenerhebung mittels Beobachtung stellt, in Abgrenzung zu Alltagsbeobachtung, einen aktiven Prozess dar, bei dem Forschungsfragen zielgerichtet und systematisch geplant, dokumentiert aufbereitet und ausgewertet werden. Dies eignet sich vordergründig für Fragen, die sich mit dem “Wie?” oder “Was geschieht hier?” befassen (Thierbach & Petschick, 2014). Beobachtungen können mit unterschiedlichen Problemen einhergehen, von denen hier auch nur einige angesprochen werden können.
Die Objektivität wird als ein zentrales Kriterium wissenschaftlicher Praxis angesehen und basiert auf der Unabhängigkeit vom Forscher sowie der Replizierbarkeit eines Ereignisses. Dem entsprechend wird eine Beobachtung als objektiver angesehen, wenn sie sich in gleicher Weise durch unterschiedliche Forscher bestätigen lässt und sie somit einer wiederholten Überprüfung standhalten kann. Diese Bedingung soll den Inhalt einer Beobachtung ins Verhältnis zu dem begrenzten Wahrnehmungsvermögen des Beobachters stellen. Die Genauigkeit und Aussagekraft einer Beobachtung hängen also auch von den eingesetzten Sinnesorganen und technischen Mitteln ab, mit denen ein Merkmal beobachtet wird. Die Objektivität von Beobachtung und damit verbundenen Aussagen, kann bspw. mathematisch in Form von Beobachterübereinstimmungskoeffizienten bestimmt und angegeben werden.
Wir setzen die Beobachtung als Forschungsmethode bislang allein in der Beurteilung des Kenntnisstandes von Befragten ein, indem wir dokumentieren, ob der Befragte beim Ausfüllen eines Fragebogens Kollegen konsultiert hat oder nicht.
3.1 Befragungsforschung
Die Standardinstrumente unserer Forschung sind derzeit qualitative und quantitative Befragungen. Qualitative Befragungen (z.B. Interviews) können gar nicht oder teilweise strukturiert sein und räumen dem Befragten viel mehr Freiheit in seinen Antwortmöglichkeiten ein. So treffen wir beispielsweise in Bezug auf die Frage “Wodurch zeichnet sich der Erfolg Ihres Unternehmens aus?” auf ganz unterschiedliche Formen, wie diese Frage vom Befragten aufgenommen und beantwortet wird.
Während die Antwort aus Interview 1: “Unsere Kunden sind von unseren Produkten und Dienstleistungen so begeistert, dass wir bereits am Limit unserer Produktionskapazität angelangt sind.” auf eine hohe Kundenorientierung hinweist, kann das Zitat aus Interview 2: “Aufgrund unserer Produktionsverfahren können wir unsere Produkte zu unschlagbaren Preisen anbieten.” eher auf eine Kostenstrategie hinweisen. Dem gegenüber lässt die Antwort aus Interview 3: “Wir sind die einzigen Anbieter für solche Produkte und Dienstleistungen am Markt.” auf eine Nischenstrategie schließen. Der Vorteil solcher offenen Fragen besteht einfach darin, dass der Forschende beschreiben kann, was von dem Befragten als relevant angesehen wird.
Der Einsatz solch qualitativer Methoden weist dabei auch immer auf eine stärker explorativ ausgerichtete Forschungsstrategie hin.
Als Nachteile solcher Datenerhebungen ist anzumerken, dass sich die Inhalte von Interviews in der Regel einer direkten Vergleichbarkeit entziehen und die Auswertung solcher Daten auch einem extrem hohen Maß an Subjektivität unterliegt. Als typische Auswertungsmethoden möchte ich in diesem Zusammenhang die Verwendung von Textanalysen erwähnen, in denen die Häufigkeit bestimmter Wortnennungen oder Themen ausgezählt werden.
Quantitativen Befragungen (z.B. Interview-Fragebogen) weisen dem gegenüber einen deutlich höheren Strukturierungsgrad auf. In solchem Fall können nicht nur angesprochene Themen und die Fragen hinsichtlich der Anzahl, Reihenfolge und des Wortlautes festgelegt sein, sondern auch die Art und Weise der Antwort. Wir sprechen hier von Antwortskalen. Der Befragte wird in diesem Fall zwischen Antwortalternativen entscheiden oder er kann eine oder mehrere Antworten aus einem Set vorgegebener Alternativen auswählen.
Dazu muss gesagt werden, dass bereits die Auswahl einer Antwortskala (Carifio & Perla, 2007; Likert, 1932) darüber entscheidet, welche Fragestellungen untersucht werden, wie die Daten später ausgewertet werden und ob bestimmte Testverfahren eingesetzt werden können. In der empirischen Forschung wird dabei beispielsweise zwischen der Beschreibung von Verteilungen und der Analyse von Stichprobenkennwerten (z.B. Mittelwert und Varianzen) unterschieden.
Im Aufbau eines strukturierten Fragebogens finden sich daher ganz unterschiedliche Komponenten. Erst einmal gibt es da ein allgemein gefasstes Thema der Befragung und eine Ansprache an die Zielgruppe. Der Angesprochene entscheidet häufig bereits hier mehr oder weniger bewusst, ob und in welcher Weise er sich zu dem Thema äußern wird.

Darüber hinaus wird dem Befragten in der Instruktion vorgegeben, in welcher Weise die Befragung verläuft und nach welchem Schema die Antworten erwartet werden. Es bildet sich also bei dem Befragten eine Sichtweise heraus, die den Befragten auch dazu bringen kann, sich der Befragung zu entziehen, weil eine spezifische Thematik aufgegriffen wird, die der Befragte nicht einschätzen kann oder will.
Außerdem können zusätzliche Angaben, durch welche die Stichprobe später eigentlich nur beschrieben und greifbarer gemacht werden soll, dazu führen, dass sich der Befragte gegenüber der Befragung verschließt. Auch eine explizit formulierte Garantie von Anonymität kann natürlich dann nicht überzeugen, wenn auf der anderen Seite konkret nach objektiven Unternehmensfakten und namentlich nach Kooperationspartnern befragt wird.
In den Datenerhebungen durch den Lehrstuhl wurden in den vergangenen 10 Jahren verschiedene Themenbereiche wie die Zusammenarbeit in Wertschöpfungsketten, Innnovationskooperationen und Digitalisierung angesprochen, in denen u.a. die strategische Ausrichtung von Unternehmen wie die Ausprägung einer Innovationsstrategie, der Pionier- und Folgerstrategie und der Kooperationsstrategie befragt wurden.
Diese Begriffe, bei denen es sich im eigentlichen Sinne um theoretische Konstrukte handelt, lassen sich tatsächlich nicht wirklich objektiv messen (Ratzmann, 2016). Das liegt darin begründet, dass es sich bei der Verwendung solcher Konstrukte nicht um die Realität an sich, sondern um Vorstellungen von Wirklichkeit (Modelle) handelt. Einige dieser Begriffe haben sich jedoch für das Verständnis von Wirklichkeit als Nützlich erwiesen und “nehmen sowohl im gesellschaftlichen als auch im betriebswirtschaftlichen Kontext eine zentrale Rolle ein” (Ratzmann, 2016 V).
So wurde der Begriff der Innovation in seinem “traditionellen Verständnis als soziologisches oder ökonomisches Phänomen aufgefasst” (Ratzmann, 2016, S. 7), der zwischenzeitlich selbst einem Wandel unterliegt, und “in unterschiedlichsten Gesellschaftsbereichen gleichsam als Leitgedanke und Deutungsmuster auftritt” (ebenda).
Innovation sind “auf zukünftiges ausgerichtet - dessen Verwirklichung kann empirisch gesichert jedoch erst ex-post beobachtet und bewertet werden” (Bormann, 2012, S. 40). Aus diesem Verständnis sind Innovationen strategische Ausrichtungen auf eine zukünftige Gegenwart, während die Forschung die Indikatoren für Innovation retrospektiv aus dem Rückblick auf vergangene Ereignisse bezieht (ebenda).
Dies führt konsequenter Weise zu der Herausforderung, wie ein solcher theoretischer Begriff von der Forschung messbar gemacht werden kann. Einerseits wurde ein Konsens durch die Veröffentlichung des Oslo-Manual gebildet, wonach “Aktivitäten und Investitionen, die auf die Forschung und Entwicklung ausgerichtet sind, als Indikatoren der Innovation angesehen” werden (Ratzmann, 2016, S. 1).
Anderseits wurden verschiedene Kategorisierungen für Innovationen vorgenommen. Eine verbreitete Konzeption in der Forschung unterscheidet Innovation auf der inhaltlichen Dimension, der Intensitätsdimension, der Subjektdimension, der Prozessdimension und der normativen Dimension (Hausschild, 2005, S. 23).
Dadurch lassen sich beispielsweise Produktinnovationen auf der inhaltlichen Dimension von Prozessinnovationen abgrenzen und Neuprodukte als radikale Innovationen in der Intensitätsdimension von Weiterentwicklungen (sogenannten inkrementellen Innovation). Darüber hinaus kann auf der Subjektdimension von Innovation unterschieden werden, für wen die Innovation Neu ist. Die prozessuale Dimension beschreibt, wo die Neuerung beginnt und endet, und die normative Dimension umfasst die Frage, ob ‘neu’ auch mit ‘erfolgreich’ (bzw. mit Verbesserung) gleichzusetzen ist.
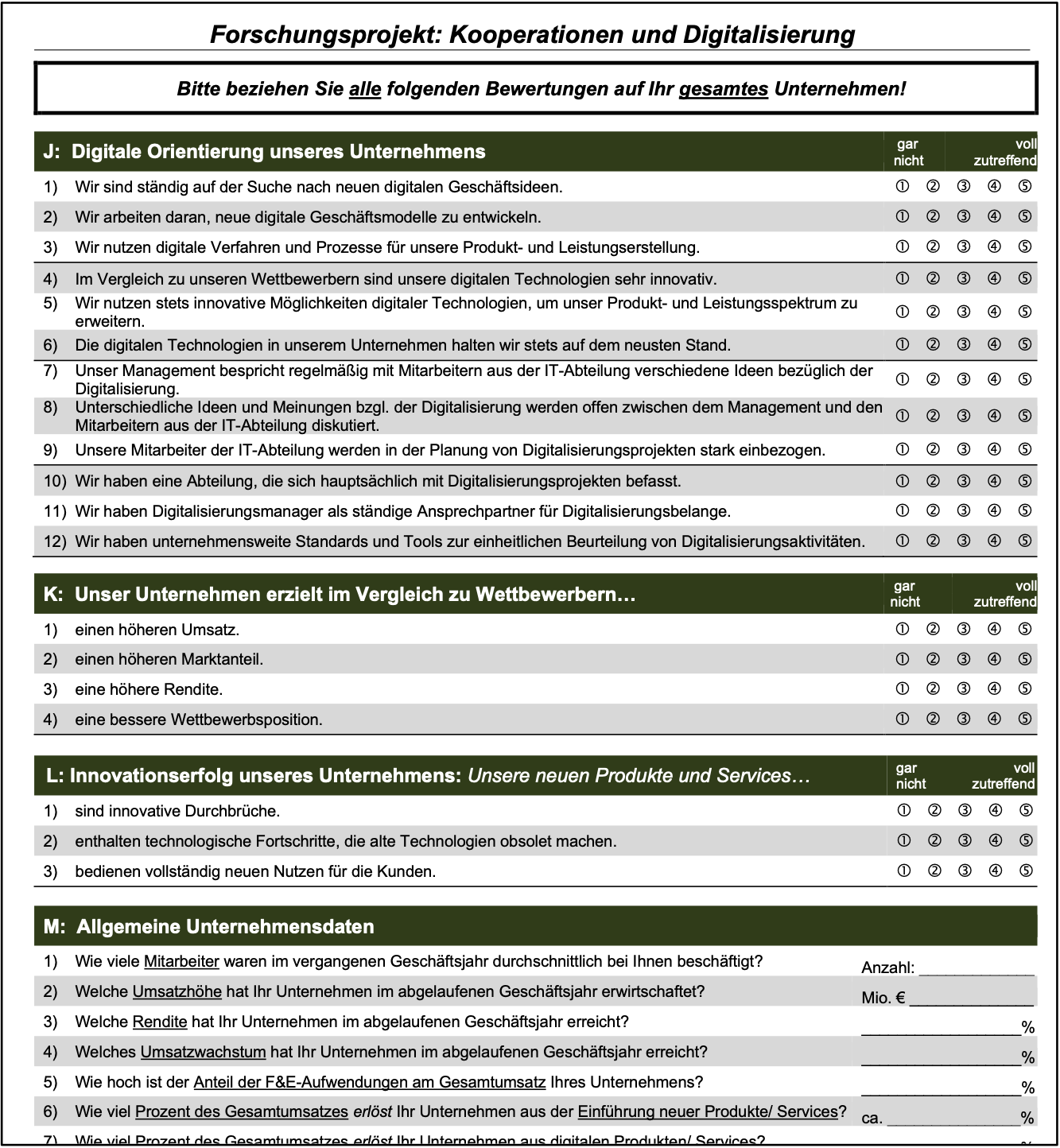
In der letzten Weiterentwicklung unseres Fragebogens werden die Teilnehmer gebeten, die folgenden Aussagen auf einer Skala von ‘eins’ bis ‘fünf’ zu beantworten, wobei die ‘eins” für vollständige Ablehnung und die ’fünf’ für vollständige Zustimmung steht:
Unsere neuen Produkte und Services …
sind innovative Durchbrüche.
enthalten technologische Fortschritte, die alte Technologien obsolet machen.
bedienen vollständig neuen Nutzen für die Kunden.
Auf der inhaltlichen Dimension ist die Innovationserfolgsmessung hier auf Produkte und Dienstleistungen ausgerichtet. Die Messung eignet sich also nicht, um Prozessinnovationen zu beurteilen. Die Intensitätsdimension ist auf radikale Innovationen ausgerichtet.
Ein Unternehmen, dass auf die Verbesserung bestehender Technologien ausgerichtet ist, würde mit dieser Messung grundsätzlich schlechter bewertet werden. Die Subjektdimension der Messung ist auf den Kunden ausgerichtet. Die prozessuale Dimension von Innovation wird durch die Obsoleszenz bestimmt, also durch die Tatsache, dass die Erneuerung die bestehende Technologie verdrängt. Die normative Dimension von Innovation wird tendenziell indirekt durch die Dominanz gegenüber dem Bestehenden bestimmt.
Mit der Befragung dieser drei Aussagen, die wir im Folgenden Items nennen werden, als Indikatoren des theoretischen Konstrukts ‘Innovationserfolg’ begegnen wir dem zweiten zentralen Gütekriterium von Datenerhebungen. Mit der Reliabilität wird die Genauigkeit einer Messung bezeichnet.
Die Klassische Testtheorie (KKT) basiert auf dem Grundsatz (Axiom), dass jede Messung auch einen Messfehler einschließt. Dieses Wissen aus dem Forschungsgebiet der Testtheorie gibt dem Forscher also zu bedenken, dass er Garnichts fehlerfrei messen kann.
Diese Tatsache kann auf den ersten Blick frustrierend wirken, bietet aber auch eine Chance. Wenn es nämlich möglich wäre, diesen Fehler zu bestimmen, könnte der wahre Wert des zu messenden Objekts als Differenz von Messwert und Messfehler bestimmt werden.
Ein zweiter Grundsatz der KTT besagt, dass es keinen systematischen Zusammenhang zwischen dem wahren Wert einer Messung und ihrem Messfehler gibt.
Daraus kann ableitet werden, dass sich bei der wiederholten Messung eines Objektes zwar immer unterschiedliche Messwerte ergeben, wenn sich jedoch der wahre Wert des zu messenden Objektes nicht verändert, dann werden die Unterschiede ausschließlich durch die Messfehler bestimmt sein. Wenn zudem angenommen werden kann, dass der Messfehler eine Normalverteilung aufweist, dann werden sich Über- und Unterschätzungen des wahren Wertes (also die Messfehler) bei wiederholten Messungen gegenseitig aufheben. Dabei ist es unerheblich, ob es sich um eine Wiederholungsmessung desselben Items oder um eine parallele Messung (mit einem ähnlichen Item) handelt.
Vor diesem Hintergrund verwenden wir sogenannte Multi-Item-Skalen und verbinden die Antworten auf die unterschiedlichen Items in einem sogenannten reflexiven Messmodell. Ein Messmodell zeigt auf, wie ein Konstrukt mit beobachtbaren Indikatoren verbunden ist.
Die Bezeichnung reflexives Messmodell verweist zudem auf die Annahme, dass die Ausprägung eines Konstruktes, in der Testtheorie als latente Variable bezeichnet, für die Ausprägungen der messbaren Variablen, in der Testtheorie als manifeste Indikatoren bezeichnet, verantwortlich ist.
Zudem kann ein Messmodell aufzeigen, auf welche Weise der resultierende Wert der latenten Variablen durch die Messwerte der manifesten Variablen bestimmt wird. Verbreitet sind z. B. die Summe, der Mittelwert und faktoren- oder regressionsanalytische Verfahren. Der resultierende Wert wird entsprechend der Zusammenfassung als Summenscore, Mittelwert, Faktorwert bzw. Wert der latenten Variablen (latent factor score) bezeichnet.
Zur Beurteilung der Reliabilität wird traditionell der Koeffizient \(\alpha\) verwendet (Cronbach, 1951). Diese Form der internen Konsistenzbestimmung basiert auf der Kovarianz zwischen den Items eines Konstruktes. Das Cronabachs-\(\alpha\) eines Messmodells ist also umso größer, je höher die durchschnittlichen Korrelationen zwischen den Items sind.
Als drittes zentrales Gütekriterium von Datenerhebungen wird die Validität (Gültigkeit) angesehen. Eine Messung wird als valide bezeichnet, wenn sie das Merkmal misst, dass sie messen soll und nicht irgendein anderes (Rost, 1996). Es gibt eine Reihe von Validierungsmöglichkeiten.
Die Validität einer latenten Variablen wird häufig in Abgrenzung zu den übrigen Variablen des Modells als in Form der Diskriminanzvalidität bestimmt. Damit soll aufgezeigt werden, dass die Items einer latenten Variablen eine hohe interne Konsistenz und gleichzeitig eine hohe Diskriminanz, also eine inhaltliche Abgrenzung, zu den Items der anderen latenten Variablen aufweisen.
Dies wird in der Regel durch mathematische Gleichungen, z.B. die Fornell-Larcker-Ratio (Fornell & Larcker, 1981) oder die Heterotrait-Monotrait-Ratio (Henseler, Ringle & Sarstedt, 2015) bestimmt. Der Begriff der Validität hat auch für viele andere Bereiche der empirischen Forschung eine hohe Bedeutung und beschreibt dann die Gültigkeit einer Messung, einer statistischen Anwendung, der Übertragbarkeit oder der Generalisierbarkeit von Ergebnissen u.s.w.
3.2 Datenqualität
Die Datenerhebung ist daher ein wichtiger, aber nicht der einzig entscheidende Faktor, welcher über die Datenqualität und die damit verbundene Aussagequalität bestimmt. An dieser Stelle sollen zumindest die Auswahl der Befragten (Stichprobenselektion) und die Situation der Testdurchführung benannt werden und Hinweise zur Berücksichtigung gegeben werden.
Traditionell gibt die Wissenschaft Bedingungen zur Bewertung von Datenqualität vor, die auf der Wahrscheinlichkeitstheorie beruhen und sich in der allgemeinen Anwendung als nützlich erwiesen haben (Bouncken, 2018). Eine der am häufigsten verwendeten Definitionen für Datenqualität bezieht sich auf die Eignung der Daten für den angestrebten Verwendungszweck (Strong, Lee & Wang, 1997; Treiblmaier, 2011).
Dementsprechend unterscheiden sich die Anforderungen an die Datenqualität, wenn es das Ziel der Forschung ist Phänomene zu erfassen, ihr Auftreten zu beschreiben oder Zusammenhänge nachzuweisen. Um ein Phänomen aufzuzeigen bedarf es insofern anderer Bedingungen, als wenn die Intention verfolgt wird, die Verteilung eines Phänomens innerhalb einer spezifischen Grundgesamtheit (auch Population genannt) darzustellen oder Zusammenhänge in Ursache-Wirkungs-Beziehungen (Kausalzusammenhängen) nachzuweisen.
Mit dem Forschungsziel, statistische Aussagen für eine Grundgesamtheit zu treffen, erfordert dies auch eine Auswahl der Befragten (Stichprobe), welche innerhalb der Grundgesamtheit vorkommen, in der Jeder (Untersuchungseinheit) auch potentiell ausgewählt werden kann und die Wahrscheinlich¬keit der Auswahl dementsprechend für Jeden bestimmt werden kann (Baker et al., 2013, S. 77). Dies entspricht der traditionellen Definition von Repräsentativität.
Beispielhaft soll dies im Folgenden auf der Ebene der deskriptiven Statistik dargestellt werden. Der Nachweis eines Merkmals bzw. Phänomens (wie z.B. einer Innovationsstrategie) beruht auf der Annahme, dass es in unterschiedlichen Ausprägungen existiert. Als elementarer Bestandteil des Nachweises wird mindestens ein Item in Form einer Frage oder einer Aussage formuliert und mit einem Antwortformat versehen.
Das Antwortformat kann in nominaler Form (‘nicht vorhanden vs. vorhanden’) oder gestuften Ratingformaten (‘nicht vorhanden, eher nicht vorhanden, teils/teils, eher vorhanden, vorhanden’) vorgegeben werden. Die Existenz eines Phänomens bedarf also mindestens des Vorhandenseins und Nichtvorhandenseins bzw. der Unterscheidung bei den Merkmalsträgern.
3.2.1 Exkurs Skalierung
Während eine nominale Antwortskala relativ einfach darüber Auskunft geben kann, ob ein Phänomen vorhanden ist oder nicht (‘ja / nein’), erfordert die Testkonstruktion von Ratingskalen umfangreichere Betrachtungen.
Ratingskalen werden - wenngleich sie ordinal skaliert sind - häufig als (metrische) Intervallskalen angesehen (Döring & Bortz, 2016, S. 251). Sie folgen eher einem natürlichen Antwortschema bei der Beurteilung von Merkmalen oder Eigenschaften und haben den Vorteil, dass sie für viele Items eines Tests oder einer Befragung gelten können.
Der Befragte kann sich dabei also auf einen Antwortmodus einstellen und einen gleichartigen Maßstab für die Beantwortung aller Items nutzen. Es können aber auch offensichtliche und spezifische Antworttendenzen auftreten, z.B. die Tendenz nur an einem Ende der Skala zu antworten, welche die Messung dann systematisch beeinträchtigen würden (Rost, 1996).
Die Qualität von Aussagen zur Häufigkeit eines Merkmals oder seiner Ausprägung sind dabei jedoch immer in Referenz zur Stichprobe zu sehen. Wenn beispielsweise 80% der Befragten in einer Stichprobe einem Item eher oder vollständig zustimmen, bezieht sich diese Aussage eben nur auf diejenigen, die auch befragt wurden.
Damit solche Informationen verallgemeinert werden können, müssten also entweder echte Zufallsstichproben aus der Grundgesamtheit gezogen werden oder es müssten weitere Informationen dargestellt werden, welche die Selektion während der Datenerhebung und weitere Merkmale der Befragten darstellen über welche dann Rückschlüsse zur Bestimmung ihrer Auswahlwahrscheinlichkeit in der Grundgesamtheit getroffen werden können.
Weitergehend lässt sich die Annahme auch auf die Qualität von Aussagen übertragen, die aus der schließenden Statistik (Inferenzstatistik) getroffen werden. Die Art und Weise wie eine Stichprobe aus der Grundgesamtheit gezogen wird, entscheidet also nach den traditionellen Forschungsvereinbarungen (Paradigma) darüber, ob die Aussagen aus der Stichprobe verallgemeinert werden können oder nicht.
Neben der Repräsentativität ist auch die Berücksichtigung hierarchischer Strukturen innerhalb der Daten von großer Bedeutung, da Schichtungen von Daten schon auf der Ebene der Datenanalyse zu systematischen Verzerrungen beitragen können.